

그래픽 설명: Claude의 점점 어리석어짐 - 절약의 비용, API 청구서가 100배 증가했습니다

몇 일전에 AMD AI 팀 리더 Stella Laurenzo가 Claude Code 공식 저장소에 "Claude Code가 복잡한 엔지니어링 작업에 사용할 수 없게 되었다"라는 제목의 이슈 보고서를 게시했습니다. 이는 사용자의 감정적인 불평이 아닌 6,800개의 세션을 기반으로 한 정량적 분석입니다. 이는 AI 커뮤니티가 가장 꺼려하는 문제들을 노출했으며, 특히 어떤 그룹의 숫자가 눈에 띕니다: Anthropic이 자원소비를 줄이기 위해 한 구성 변경으로 이 팀의 API 월간 청구서를 345달러에서 42,121달러로 증가시켰습니다.
Laurenzo의 팀은 235,000회의 도구 호출, 18,000개의 제안어를 추적하고, Claude Code의 2026년 2월 이후의 시스템 성능 저하를 기록했습니다. 이 보고서는 그 후 The Register에 의해 보도되어 개발자 커뮤니티에서 두 주 동안 계속되는 논란을 일으켰습니다.
Anthropic Claude Code 팀 리더인 Boris Cherny는 Hacker News에서 설명했습니다. 2월 9일 Opus 4.6과 함께 출시될 때, 모델이 스스로 사고 시간을 결정하는 "적응적 사고" 메커니즘이 기본으로 활성화되었습니다. 3월 3일, Anthropic은 기본 사고 강도를 85로 낮췄습니다. 이러한 조정의 공식적인 설명은 "지능, 지연 및 비용 사이의 최적 균형점"입니다. 이 두 번의 조정의 실제 효과는 데이터로 명확히 보여집니다.
사고 깊이, 4분의 3 하락
Stella Laurenzo의 GitHub 이슈 데이터에 따르면, Claude Code의 평균 사고 깊이는 두 달 사이 세 단계의 붕괴를 겪었습니다. 1월 말에는 2,200 문자의 고품질 기간이었지만, 2월 말에는 720 문자로 떨어져 전체에서 67% 감소했습니다. 3월에는 더욱 축소하여 560 문자로, 정점에서 75%가 감소했습니다.
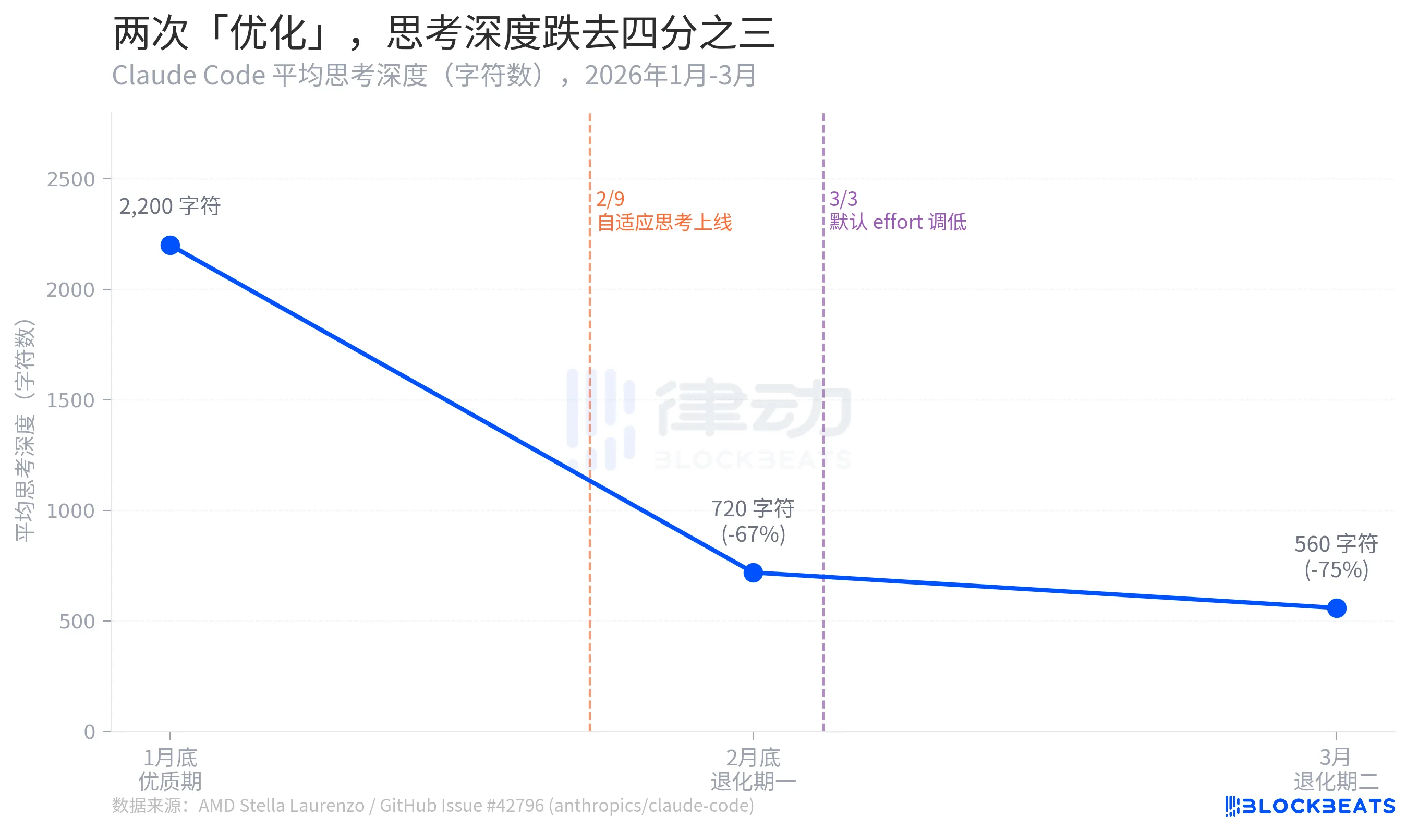
여기서 사고 깊이는 모델이 답변을 제공하기 전에 얼마나 많은 "내부 추론"을 투자하는지를 반영하는 지표입니다. 2,200 문자와 560 문자 간의 차이는 대략적으로 "게재 후에 답변"에서 "두 번 생각하지 않고 말하기"로의 퇴화에 해당합니다.
Laurenzo는 또한, 3월 초에 출시된 "사고 내용 숨김" 기능(redact-thinking-2026-02-12)이 정확히 이 기간에 모델의 사고 프로세스를 가리고 사용자가 축소를 직관적으로 인지할 수 없게 했다고 지적했습니다. Boris Cherny는 이것이 단지 인터페이스 변경이며 하부 추론에는 영향을 주지 않는다고 주장했습니다. 두 설명은 기술적으로 모두 타당하지만 사용자 관점에서는 효과에 차이가 없습니다.
Boris Cherny는 나중에 직접 최대 노력을 수동으로 다시 설정해도, 적응적 사고 메커니즘은 여전히 일부 라운드에서 추론 부족을 할당하고 환상적인 콘텐츠를 생성할 수 있다고 인정했습니다. "최대 노력 복구"가 완전한 해결책은 아니며, 이것은 단지 조절기를 원 위치에 가깝게 돌려놓는 것뿐이며, 원래의 결정적 상태로 복원하는 것이 아닙니다.
「리서치 프로그래머」에서 「블라인드 에딧 프로그래머」로
Stella Laurenzo의 보고서에는 생각 깊이보다 명백한 세부 사항이 있습니다: 코드를 수정하기 전에 모델이 관련 파일을 스스로 읽는 횟수.
GitHub Issue 데이터에 따르면, 품질이 좋은 기간의 평균 읽기/수정 비율은 6.6이며, 코드를 수정하기 전에 모델은 평균적으로 6.6개의 파일을 읽어 문맥을 파악합니다. 퇴화 단계에서이 숫자는 2.0까지 떨어지며, 70% 감소합니다. 더 심각한 것은 코드 수정의 약 1/3가 모델이 대상 파일을 읽지 않은 상태에서 직접 수정됩니다.
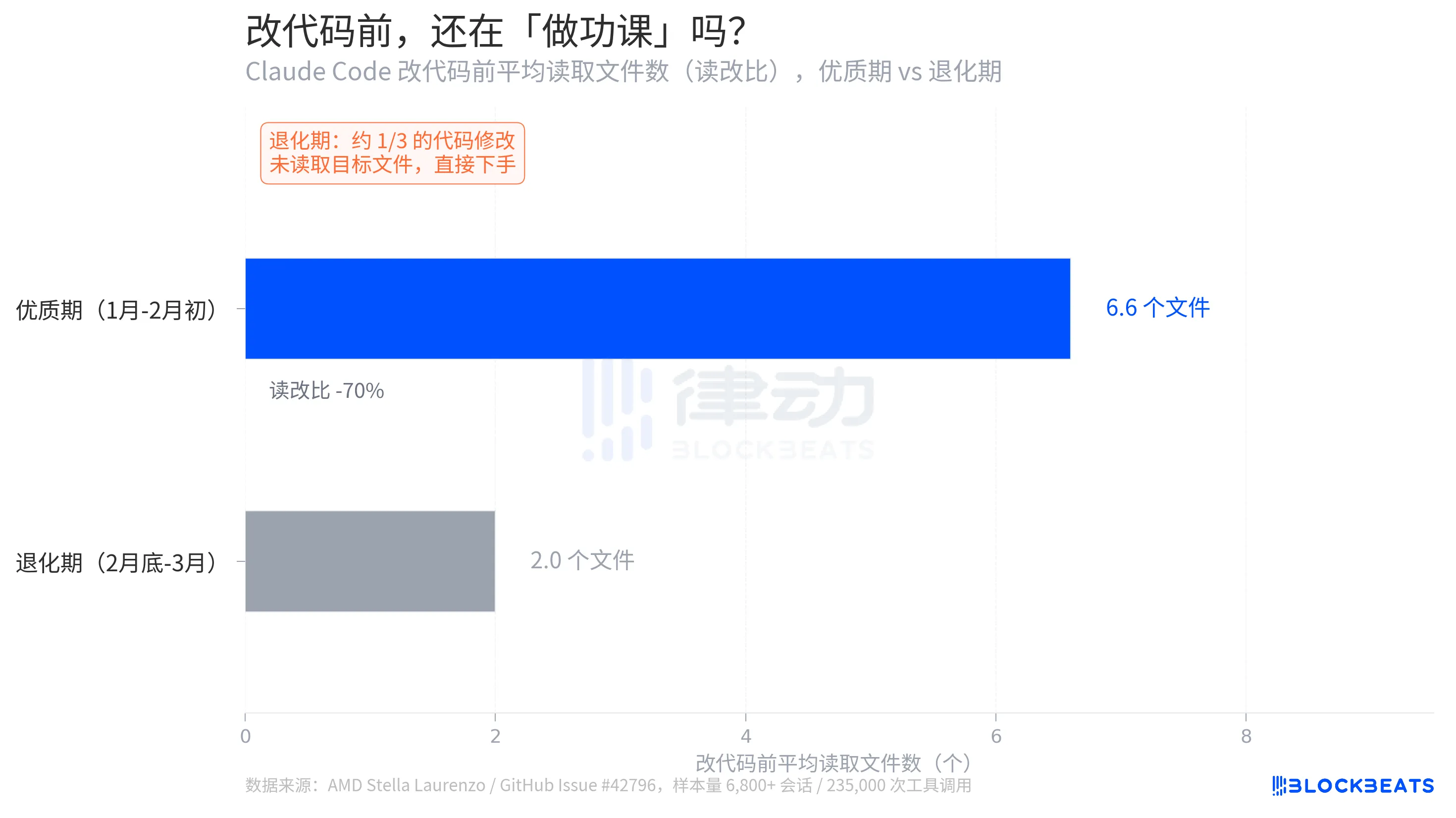
Laurenzo는 이를 "블라인드 에딧"이라고 부릅니다. 엔지니어링 적으로, 이는 함수 서명을 보지 않고 변수 유형을 모르면서 코드를 작성하기 시작하는 프로그래머에 해당합니다. "우리 팀의 모든 수석 엔지니어가 이와 유사한 경험을했습니다." 그녀는 보고서에서 이렇게 쓰고 있습니다. "Claude는 이제 복잡한 엔지니어링 작업을 수행할 수 없습니다."
읽기/수정 비율이 6.6에서 2.0으로 감소하는 것은 행동 지표의 변화로 보이지만, 실제로는 작업 성공률의 붕괴입니다. 현대 코드베이스의 복잡성은 모든 수정이 서로 의존하는 여러 파일을 포함하도록 결정합니다. 문맥 탐색을 건너뛰고 직접 수정하는 것은 "답을 잘못했다"는 것이 아니라 "보이기엔 옳지만 하위에서 새로운 오류를 유발할 수 있는" 것입니다. 이러한 유형의 오류 해결 비용은 명확한 오답 한 번의 비용보다 훨씬 더 높습니다.
「절약」이라는 것, 거꾸로 계산
이는 전체 이벤트에서 가장 직관에 반하는 숫자의 그룹으로, 동일한 GitHub Issue 데이터에서 나온 것입니다: Stella Laurenzo 팀의 Claude Code API 월 호출 비용은 2026년 2월의 345달러에서 3월에 42,121달러로 122배 증가했습니다.
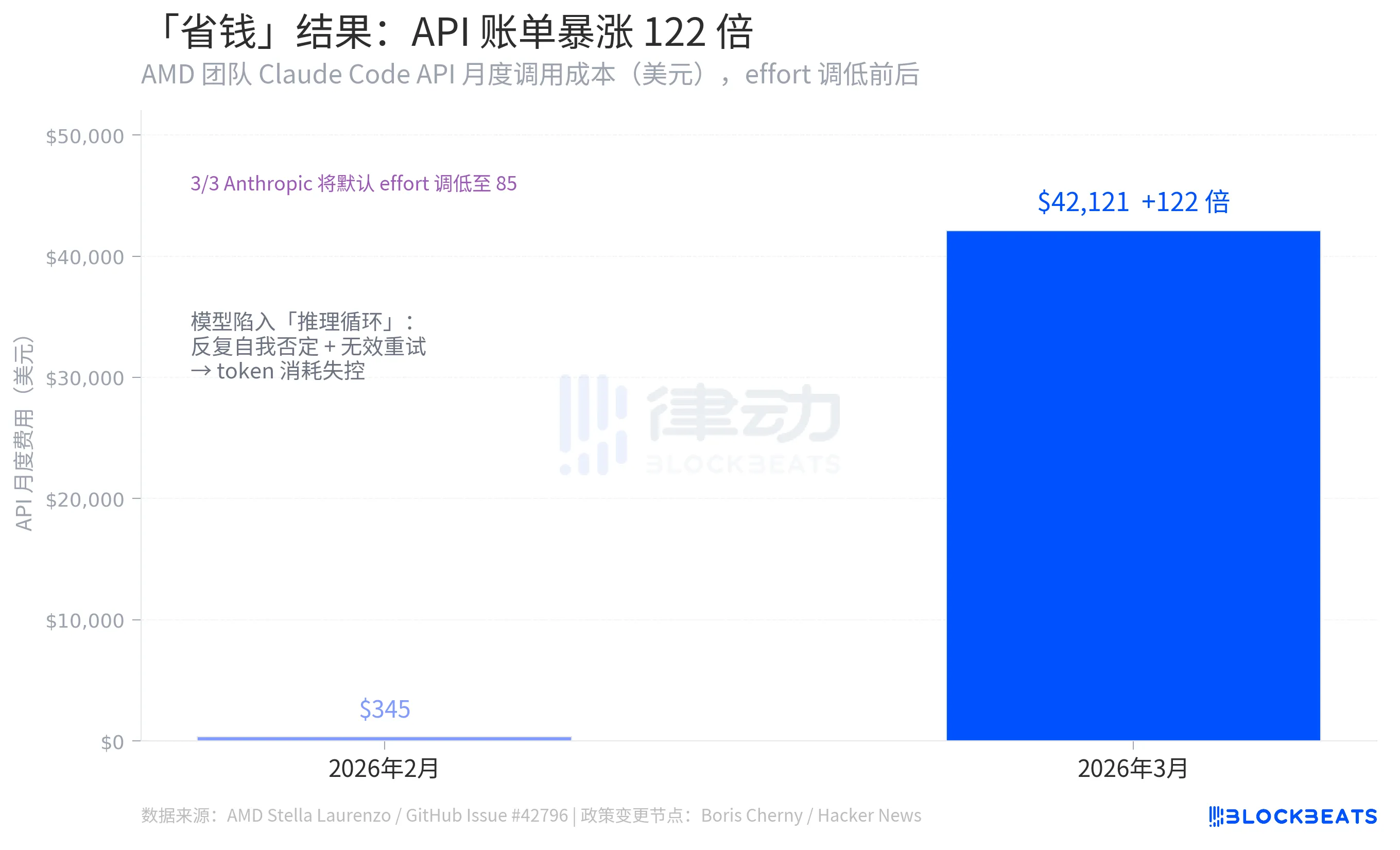
Anthropic은 노력을 줄이는 논리로 한 번의 호출에서 토큰 사용량을 줄여 비용을 절감하려고 했습니다. 그러나 결과는 반대였습니다. 이유는 모델이 퇴화되면 "추론 루프"가 많이 발생하여, 단일 응답에서 반복적으로 자기 부정하며 계속 다시 시작하고, 사용된 토큰이 절약된 양을 훨씬 초과합니다. Stella Laurenzo의 데이터에 따르면, 사용자가 작업을 더 이상 수행하지 않는 비율이 12배 증가했으며, 개발자는 계속 개입하고 수정하고 다시 제출해야 했습니다.
논리적 배경에는 시스템적인 오류가 있습니다. 복잡한 작업에서는 계산 능력을 감추는 것이 비용을 단순 비례해서 낮추는 것만큼 간단하지 않습니다. 어떤 사고 임계값 이하로 내리면, 모델은 잘못된 방향으로 향하게 되며 총 비용이 오히려 증가합니다. 노력을 줄이면 간단한 쿼리에서 비용을 절약할 수 있지만, 코드 엔지니어링 작업에서는 청구서가 급증합니다.
「저지능화」라는 것, GPT-4가 세 년 전에 한 번 따라했었습니다
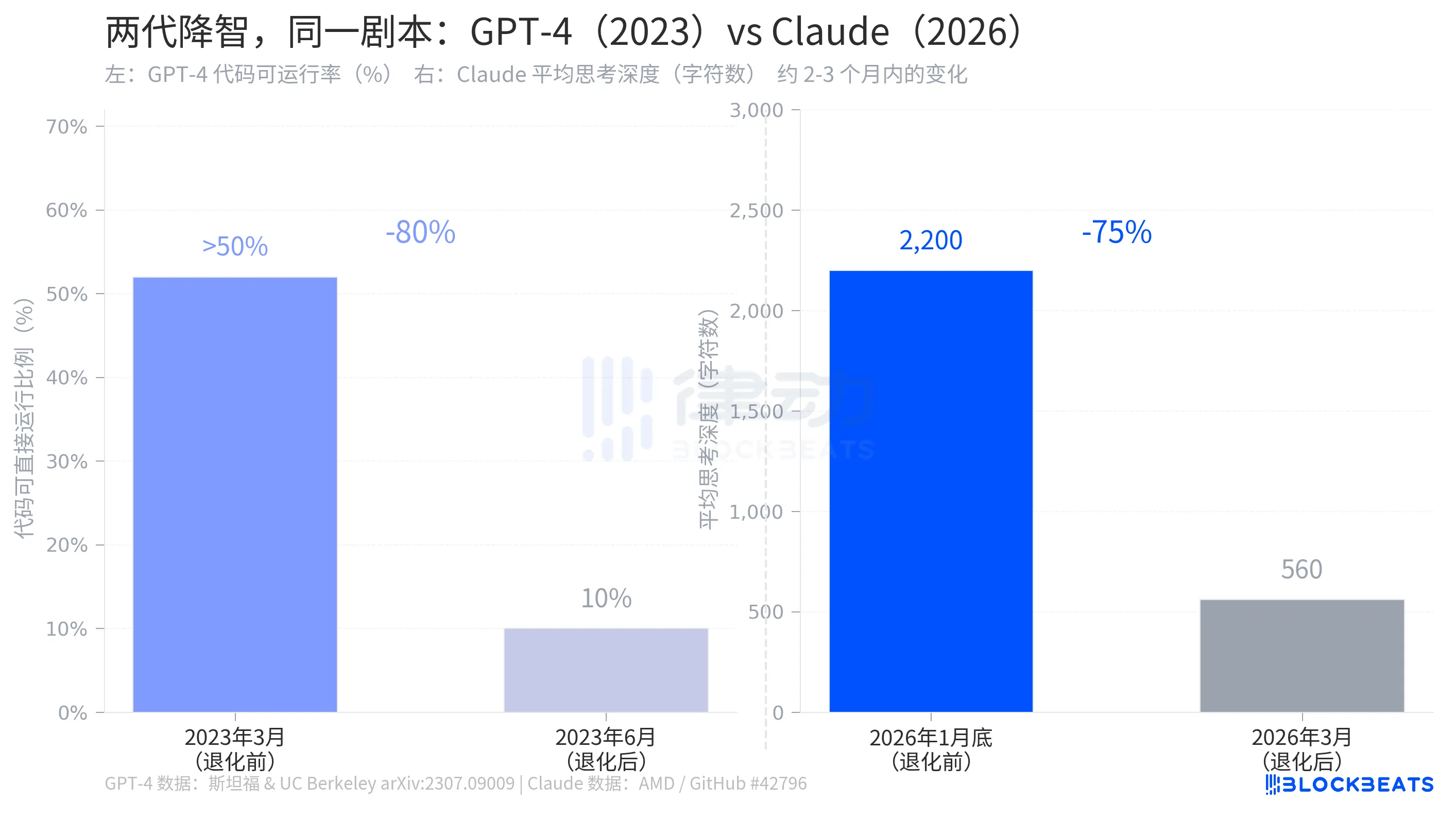
2023년 7월, 스탠퍼드 대학과 캘리포니아 대학 버클리 캠퍼스의 연구팀이 arXiv에 발표한 <How is ChatGPT's behavior changing over time?> 논문에서는 GPT-4에서 같은 일이 벌어지는 과정을 기록했습니다.
해당 연구 데이터에 따르면, 2023년 3월에 생성된 GPT-4의 코드 중 50% 이상이 직접 실행될 수 있었습니다. 그러나 6월에는 해당 비율이 10%로 떨어졌으며, 이는 80%의 하락률을 보였으며, 이는 세 달의 시간 경과로 이루어졌습니다. 동시에 소수 인식 정확도는 97.6%에서 2.4%로 하락했습니다. OpenAI의 반응은 Anthropic과 매우 유사했습니다: 백그라운드에서 최적화 조정이 있었으며, 이는 정상적인 반복 개선에 해당합니다.
두 가지 이야기의 구조는 거의 동일하며, 한 AI 기업이 모델 능력에 영향을 미치는 매개변수를 조용히 조정했으며, 사용자가 이를 인지했지만, 기업은 조정했다고 인정했지만, 그 이유로 "더 합리적인 리소스 할당"이 있다고 설명했습니다. GPT-4의 저하는 2023년에 발생했으며, Claude의 저하는 2026년에 발생했으며, 두 사건 간의 간격은 세 년이며, 대본은 동일합니다.
이것은 특정 회사의 특별한 실수가 아닙니다. AI 구독 모델의 경제적 논리로 인해 판단 비용이 가격 책정 범위를 초과하는 경우, 제조업체가 직면하는 압력은 동일합니다. 기본 사고 강도를 낮추는 것은 현재 비용과 성능 사이에서 가장 쉽게 조절할 수 있는 설정입니다. 사용자가 인식하는 것은 모델이 "더 어려워졌다"는 것입니다. 제조업체가 적재한 것은 각 호출의 마진 토큰 비용을 줄이는 것입니다.
Boris Cherny는 기술적인 해결책을 제시했으며, 사용자는 /effort high 명령 또는 구성 파일을 수정하여 수동으로 사고 강도를 최고 수준으로 복원할 수 있습니다. 이 해결책은 기술적으로 실행 가능하지만, 동시에 "최고 성능"이 기본 설정이 아님을 의미합니다.
345달러에서 42,121달러까지, 소비된 것은 예산 뿐만 아니라 한 가지 가정입니다: 제조업체가 한 기본 설정 변경은 사용자의 사용 효과를 더 좋게 만들기 위해 이루어졌습니다.
BlockBeats 공식 커뮤니티에 참여하세요:
Telegram 구독 그룹:https://t.me/theblockbeats
Telegram 토론 그룹:https://t.me/BlockBeats_App
Twitter 공식 계정:https://twitter.com/BlockBeatsAsia






