

2026년, 평범한 사람이 거래 신호를 어떻게 포착합니까?

원문 제목: 50개의 약한 신호를 결합하여 하나의 우승 거래로의 수학
원문 작성자: Roan, 암호화 분석가
번역, 주석: MrRyanChi, insiders.bot
서문
작년, 트럼프-마스크 대학교 @Wharton에서의 첫 주 교육에서, 저는 @DakshBigShit과 함께 @insidersdotbot을 설립했습니다. 워튼 비즈니스 스쿨의 훌륭한 토양과 뉴욕 인근의 지리적 이점 덕분에, 저는 4개월 만에 수십억 달러 규모의 헤지펀드 관리 파트너들과의 깊은 대화를 나눌 수 있었습니다.
이후, 홍콩에서 창업에 전념하며, insiders.bot은 이미 주목받기 시작했고, 이를 통해 아시아의 양자 기관들과도 심층적인 소통 기회를 갖게 되었습니다.
이 과정에서 가장 많이 들은 단어 중 하나는 "신호"입니다.
진입 신호, 청산 신호 등. 이 과정에서, 소매 업자와 기관 간의 가장 큰 차이는 정보량도 자금량도 아닌 사고 방식임을 발견했습니다. 소매 업자는 항상 그 "완벽한 신호"를 찾으려 하지만, 기관은 여러 개의 "그다지 좋지 않은" 신호들을 하나로 뭉쳐주는 수학 엔진을 사용합니다.
Binance, OKX, Bitget 등 거래소의 월렛도 다양한 신호 알림 콘텐츠에 빠르게 참여했습니다.
insiders.bot이 초기에 설립된 시기에는 우리도 "신호 봇"으로 등장했습니다. 그리고 우리가 그 당시 가장 인기 있던 v1.2 신호는 여러 스마트 머니 신호를 종합한 신호로, 여러 체인 상 거장들로부터 찬사를 받았습니다. 시장 거래자들이 가장 좋아하는 알림 시스템 @poly_beats도 본질적으로는 신호입니다.
이 RohOnChain의 글은 신호라는 프레임워크를 가장 명확하게 설명한 글 중 하나입니다. 양자 배경이 전혀 없더라도 처음부터 끝까지 이해할 수 있도록 많은 시간을 들여 다시 작성, 보충하고 주석을 달았습니다.
제 1부: 존재하지 않는 "완벽한 신호"
20년간 시스템 거래 분야에서 활동한 한 헤지펀드 파트너와 대화를 나누면서, 몇 달 동안 생각해 본 말을 들었습니다.
그 날 그는 나와 마주 앉아 우리가 논의하는 전략을 지켜보며 차분하게 말했다:
“너는 항상 그 영원히 옳은 유일한 신호를 찾으려고 애를 쓰지. 하지만 그런 건 사실 존재하지 않아. 진정으로 이길 수 있는 거래 팀은 많은 조금씩 정확한 신호를 올바르게 조합할 수 있는 팀들이야.”
그가 설명한 이것은 양자 투자계에 Jargon이라는 매우 추상적인 전문 용어가 있어요:
알파 조합 (Alpha Combination).
이 프레임워크는 한 갈래의 강과 기껏해야 방향은 맞췄지만 여전히 흘러간 사람들을 엄격하게 구분합니다.
이 글을 읽으면서 이 다섯 가지 사실을 이해하게 될 겁니다:
1. 왜 50개의 약한 신호 조합이 하나의 강한 신호를 압도하는지?
2. “액티브 매니지먼트의 기본 법칙”이 무엇인가요?
3. 기관은 결국 어떤 11 단계로 말도 안 되는 신호를 고승률 전략으로 만들까요?
4. 왜 여러분은 방향을 제대로 맞췄음에도 결국 돈을 잃게 될까요?
5. 이 시스템을 Polymarket에 완벽히 적용하는 방법은 무엇인가요?
만약 여러분이 진정으로 여러분만의 거래 우위를 구축하고 싶다면 어떤 섹션도 건너뛰지 마세요. 이 프레임워크는 당신이 이 다섯 부분을 연결해 보는 경우에만 진정한 힘을 발휘합니다.
그리고 부연하자면, 이 글은 AI 에이전트에게 최적화된 구조로 작성되었어요. 여러분의 Claude, Manus 또는 어떤 AI에게라도 주입하고 당장 여러분만의 양자 모델을 구축하기 시작하세요.
1.1 신호란 무엇인가?
수학적으로 깊게 들어가기 전에, 먼저 우리의 언어를 통일해야 합니다: 신호란 무엇인가요?
일상에서 우리는 종종 “이 코인이 올라갈 것 같아” 또는 “트럼프가 당선될 거라고 나는 확신해”라고 말합니다. 이를 의견이라고 합니다. 의견은 모호하고 주관적이며 정확한 백테스트가 불가능합니다.
하지만 기관의 양자 프레임워크에서 신호란 미래 가격이나 확률 변동과 통계적으로 반복 가능한 관계가 있는 측정 가능하며 신뢰할 수 있는 데이터 포인트입니다.
그것은 세 가지 조건을 충족해야 합니다:
가용성 있음: 이는 구체적인 숫자여야 합니다. 예를 들어, "지난 24시간 거래량이 3배 증가했습니다"와 같이 명시되어야 하며, "최근 논의하는 사람이 많아 졌다"와 같이 모호해서는 안 됩니다.
방향성이 있음: 이는 다음 가격이 상승인지 하락인지, 또는 확률이 증가하는지 감소하는지를 나타내야 합니다.
반복 가능함: 이는 독립적인 사건이 아니어야 하며, 역사적으로 여러 차례 발생하고 각 발생 이후 시장이 유사한 반응을 보여야 합니다.
예를 들어, Binance에서 몇 명의 대형 거래자가 연이어 매수 주문을 넣었고, 그 양이 신호입니다.
예를 들어, 우리 @insidersdotbot의 v1.2 Skew(스큐, Smart Money의 Long vs Short 비율)도 신호입니다.
Polymarket의 예를 들어보겠습니다: 과거 70% 이상의 승률을 가진 스마트 머니 지갑이 갑자기 어떤 이색 계약에 5만 달러를 베팅한 경우가 있습니다. 이것은 매우 표준적인 "미시 구조 신호"입니다. 이것은 구체적입니다(5만 달러), 방향성이 있습니다(그가 선택한 옵션), 그리고 반복 가능합니다(과거의 모든 베팅 내역을 다시 테스트할 수 있습니다).
신호가 무엇인지 이해했으므로, 다음 질문을 살펴보겠습니다: 귀하의 신호는 얼마나 정확한가요?
1.2 IC란 무엇인가요? 귀하의 신호의 "성적표"
거래를 한 모든 사람은 다음과 같은 순간을 경험했습니다: 귀하의 분석이 분명히 옳았고, 가격도 실제로 귀하의 예측 방향으로 이동했지만 최종적으로는 손실이 발생했습니다.
이는 운이 나쁜 것이 아닙니다. 단일 신호에만 의존하여 거래할 때 손실이 거의 수학적으로 불가피합니다. 이러한 이유를 이해하는 것은 다음 모든 내용의 기초입니다.
양자화 연구에서는 각 신호에 대해 정보 계수(IC)라는 정확도 측정 지표가 있습니다.
IC는 귀하의 예측과 시장 실제 동향 사이의 관련성을 측정합니다. 이를 귀하의 신호의 "성적표"로 생각할 수 있습니다.
IC가 실제로 어떻게 계산되는지 알아보겠습니다. 한 단계씩 살펴보겠습니다.
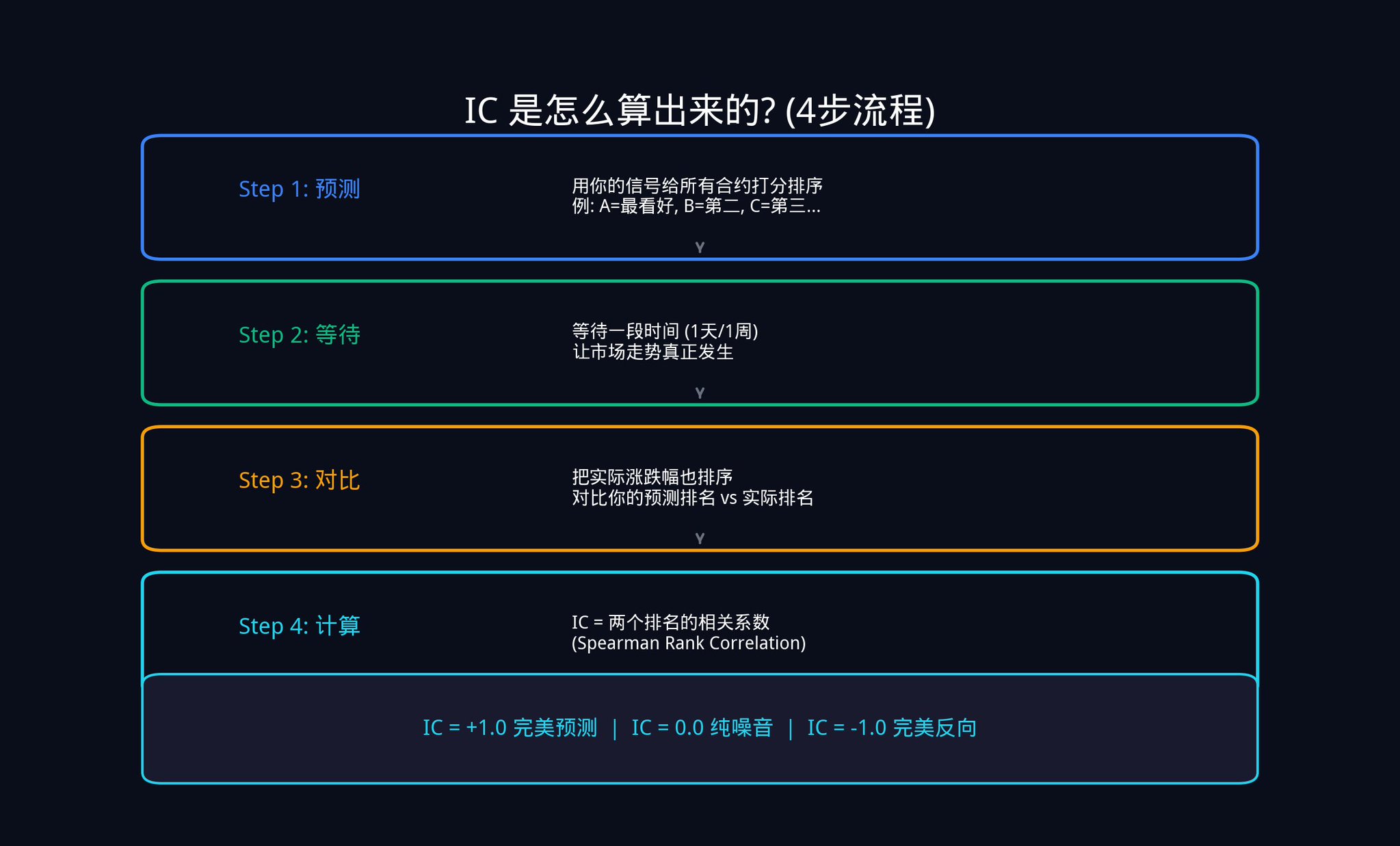
첫 번째 단계, 예측. 오늘 Polymarket에는 20개의 활성 계약이 있습니다. 여러분은 시그널을 사용하여 이 20개 계약에 대해 순위를 매깁니다. 계약 A가 가장 가능성이 높다고 생각되면 1위로, 계약 B는 2위로, 이와 같이 20위까지 계속합니다.
두 번째 단계, 기다림. 하루, 일주일 또는 설정한 어떤 시간 프레임 동안 시장이 실제로 변동하도록 합니다.
세 번째 단계, 비교. 설정한 시간이 경과한 후, 이 20개 계약의 실제 가격 변동률을 순위 매깁니다. 가장 많이 올랐으면 1위, 두 번째로 많이 올랐으면 2위, 이와 같이 계속합니다.
네 번째 단계, 계산. 이제 두 가지 순위가 있습니다: 첫 번째는 처음에 예측한 순위, 두 번째는 실제 결과 순위입니다. 계산해야 할 것은 이 두 순위 간의 관련성입니다.
여기서 사용되는 것은 통계학에서의 스피어만 순위 상관 계수(Spearman Rank Correlation)입니다.
무서운 것처럼 들릴 수 있지만, 실제로 그것은 매우 간단한 논리입니다:
· 만약 여러분이 예측한 1위 계약이 실제로 가장 많이 오르면서, 여러분이 예측한 2위가 두 번째로 많이 오른다면, 여러분의 두 순위는 높은 관련성을 가집니다. 상관 계수는 거의 +1.0에 가깝습니다.
· 완전히 반대인 경우(여러분이 상승을 예측한 것이 사실은 하락), 상관 계수는 -1.0에 가깝습니다.
· 아무런 관련이 없는 경우, 상관 계수는 0.0이며, 여러분의 시그널은 주사위 던지기와 차이가 없다는 것을 의미합니다.
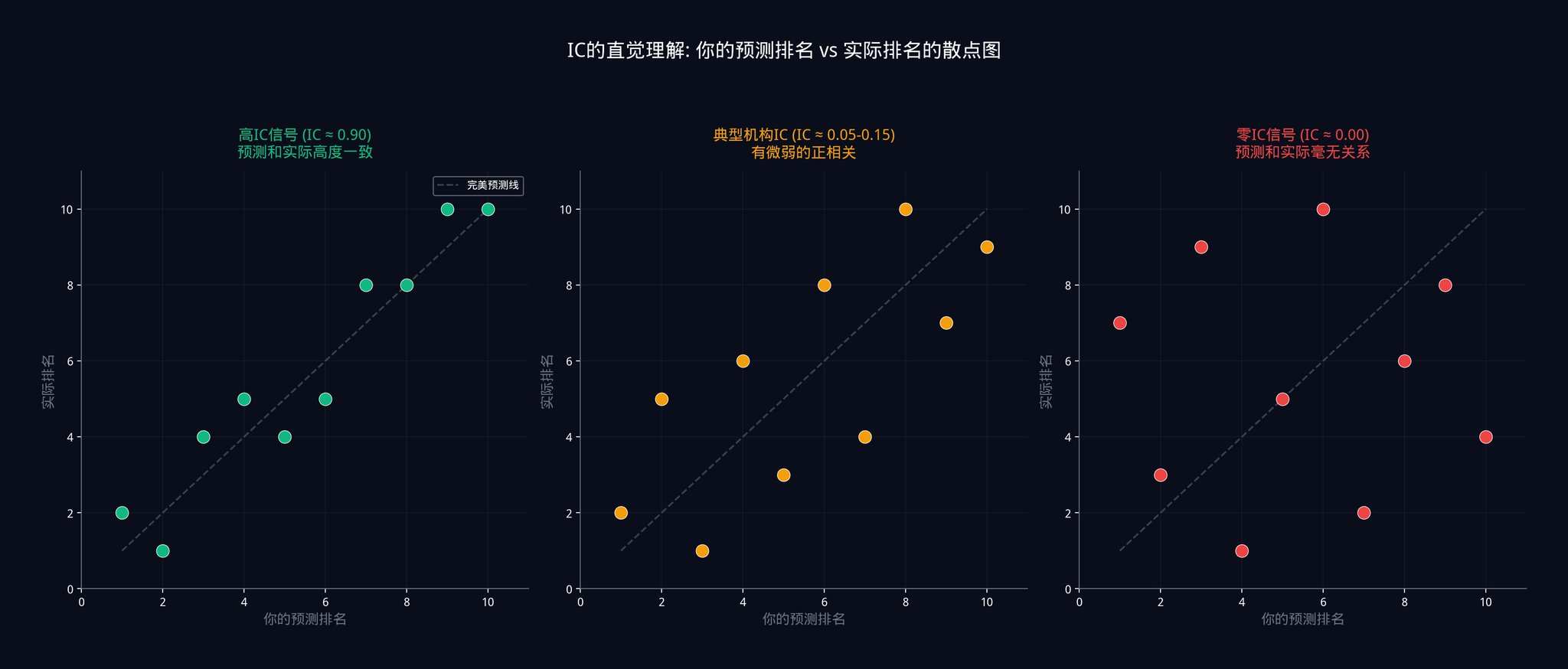
위의 그림은 세 가지 다른 IC 수준에서 예측 순위와 실제 순위 간의 관계를 보여줍니다.
왼쪽은 IC가 거의 0.9인 경우로, 점들이 거의 대각선에 놓이며, 예측과 실제가 매우 일치함을 보여줍니다.
가운데는 IC가 0.05에서 0.15 사이인 경우로, 점들이 곳곳에 흩어져 있으며 매우 약한 양의 상관 관계만 있습니다.
오른쪽은 IC가 0인 경우로, 완전히 무작위이며 규칙이 전혀 없습니다.
왜 순위를 사용해야 하고 수치를 직접 사용하면 안 되는가?
랭킹은 이상값에 민감하지 않기 때문에 중요합니다. 예를 들어 어떤 스마트 계약이 블랙 스완 사건으로 500% 급등했다고 가정해보세요. 숫자로 상관 관계를 계산하면, 이상점이 전체 결과를 왜곡하게 됩니다. 하지만 랭킹을 사용하면 해당 이상값은 그저 "1등"에 불과하며, 다른 스마트 계약들의 랭킹에 영향을 주지 않습니다. 이것이 기관들이 피어슨 상관 계수 대신 스피어만 순위 상관 관계를 선호하는 이유입니다.
실제로, 당신은 하루의 IC만 계산하는 것이 아닙니다. 이 프로세스를 여러 날짜 (예: 100일) 동안 반복한 다음 평균을 취합니다. 이 평균 값이 바로 귀하의 신호의 평균 IC입니다.
그렇다면, 월가의 최고 거래소, 수십억 달러 가치의 신호를 실행하는 그들의 IC는 얼마인가요?
답: 0.05에서 0.15 사이입니다.
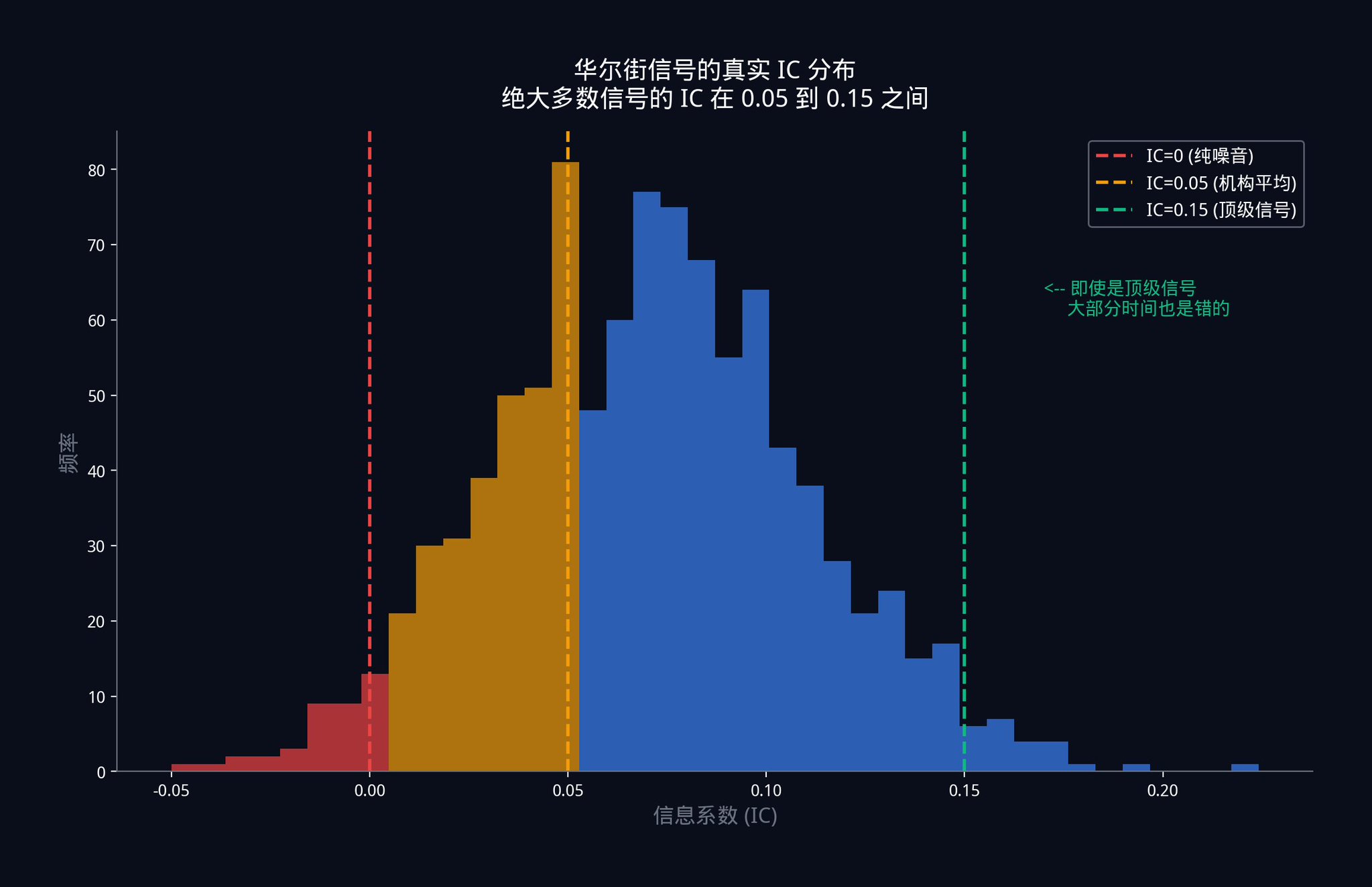
이 숫자를 한 번 더 살펴봐 주세요. 기관 수준에서 사용되는 가장 최상위 단일 신호는 대부분 시간에 걸쳐 틀립니다. 가끔 틀리는 것이 아니라 대부분의 시간에 틀립니다.
IC = 0.05은 무엇을 의미하나요?
이것은 귀하의 신호와 시장 실제 움직임 간에 5%의 상관 관계만 있다는 것을 의미합니다. 산점도를 그려보면, 점들이 거의 무작위로 분포되어 있으며 매우 약한 양의 경향만이 존재합니다.
이것은 신호가 무력해졌다는 것이 아닙니다. 이것은 경쟁적인 시장의 본질입니다.한 번 발견되는 강력한 이점은 자본이 급격히 투입되어 그 이점이 다 쥐어질 때까지 압축되어 매우 낮은 수준으로 밀려납니다.효율적인 시장에서는 IC 0.05를 안정적으로 유지하는 것이 이미 매우 큰 성취입니다.
그렇다면 단일 신호가 이토록 약한데, 기관들은 어떻게 돈을 벌까요?
1.3 기관의 메인 킬러: 액티브 매니지먼트의 기본 법칙
1994년, 양자적 연구 선구자 림차드 그리놀드와 론날드 칸은 그들의 저서 "Active Portfolio Management"에서, 자산 관리 업계 전반을 변화시킨 공식을 제시했습니다:
IR = IC x √N
이 공식은 활성 관리의 기본 법칙(The Fundamental Law of Active Management)으로 알려져 있습니다.

그렇다면 이 세 글자는 각각 무엇을 나타내는 걸까요?
IR(Information Ratio, 정보 비율)은 당신의 전체 거래 시스템의 '종합 성적'을 의미합니다. 이는 당신이 한 단위의 위험을 감수할 때 얼마나 벌 수 있는지를 측정합니다. 이는 '가성비' 지표로 생각할 수 있습니다. 높은 IR은 당신의 전략이 더 '안정적'임을 나타내며, 양자 금융 분야에서 IR이 1.0일 때 이미 최고 수준으로 간주됩니다.
IC(Information Coefficient, 정보 계수)는 방금 전 한 시간 동안 설명한 것입니다: 당신의 단일 신호의 평균 정확도입니다.
N은 당신의 포트폴리오의 독립적인 신호의 수입니다. 여기서 '독립적'인 이 단어가 매우 중요합니다. 왜 그런지에 대해 제가 네 번째 부분에서 자세히 설명하겠습니다.
지금, 이 공식의 핵심 정보는: 전체 시스템 성능(IR)은 개별 신호의 정확도(IC)에 신호 수의 제곱근(√N)을 곱한 것과 동일합니다.
그렇다면, 질문이 제기됩니다. 왜 제곱근인가요? 왜 N을 곱하지 않는 건가요? 이 질문은 매우 중요하며, 저는 여러분이 0부터 이를 유도하는 데 도움을 드리겠습니다.
동전 던지기를 상상해보십시오. 앞면이 나오면 1달러를 딴다면, 뒷면이 나오면 1달러를 잃습니다.
만약 한 번만 던진다면, 결과는 완전히 무작위입니다. 1달러를 따거나 1달러를 잃게 될 것입니다.
그러나 100번을 던진다면 어떨까요? 전체 수익의 기댓값은 0입니다(앞 뒤 각각 50회씩 나오기 때문에). 그러나 중요한 것은 변동성입니다. 통계학은 우리에게 100번 독립적인 동전 던지기의 총 변동성이 100이 아니라 √100 = 10임을 알려줍니다.
왜냐하면 완전히 독립적인 무작위 사건이 함께 쌓이면서 그들의 소음이 일부 상쇄되기 때문입니다. 앞과 뒤가 번갈아 나오며, 한 방향으로만 계속 나아가는 것이 아니기 때문입니다. 그래서 전체 변동이 전체 횟수보다 느리게 증가하는 것입니다.
이제 이 논리를 신호 조합에 적용해봅시다. N개의 독립적인 신호가 있다고 가정해봅시다. 각 신호는 약간의 긍정적 장점(IC가 0보다 큼)을 갖고 있습니다.
당신의 총 이익(모든 신호의 이점의 합)은 N에 따라 선형적으로 증가합니다. 각각의 신호가 추가됨에 따라 약간의 이점이 생기기 때문입니다. 10개의 신호의 총 이점은 1개의 신호의 10배입니다.
하지만 총 위험(모든 신호의 잡음이 적용된 값)은 √N에 따라만 증가합니다. 독립적인 잡음이 상쇄되기 때문입니다. 10개의 독립적인 신호의 총 잡음은 1개의 신호의 10배가 아닌 약 3.16배 정도입니다(√10 ≈ 3.16).
그러므로, 당신의 정보 비율 = 총 이익 / 총 위험 = (IC x N) / (σ x √N) = IC x (N / √N) = IC x √N.
이것이 IR = IC x √N의 기원입니다.
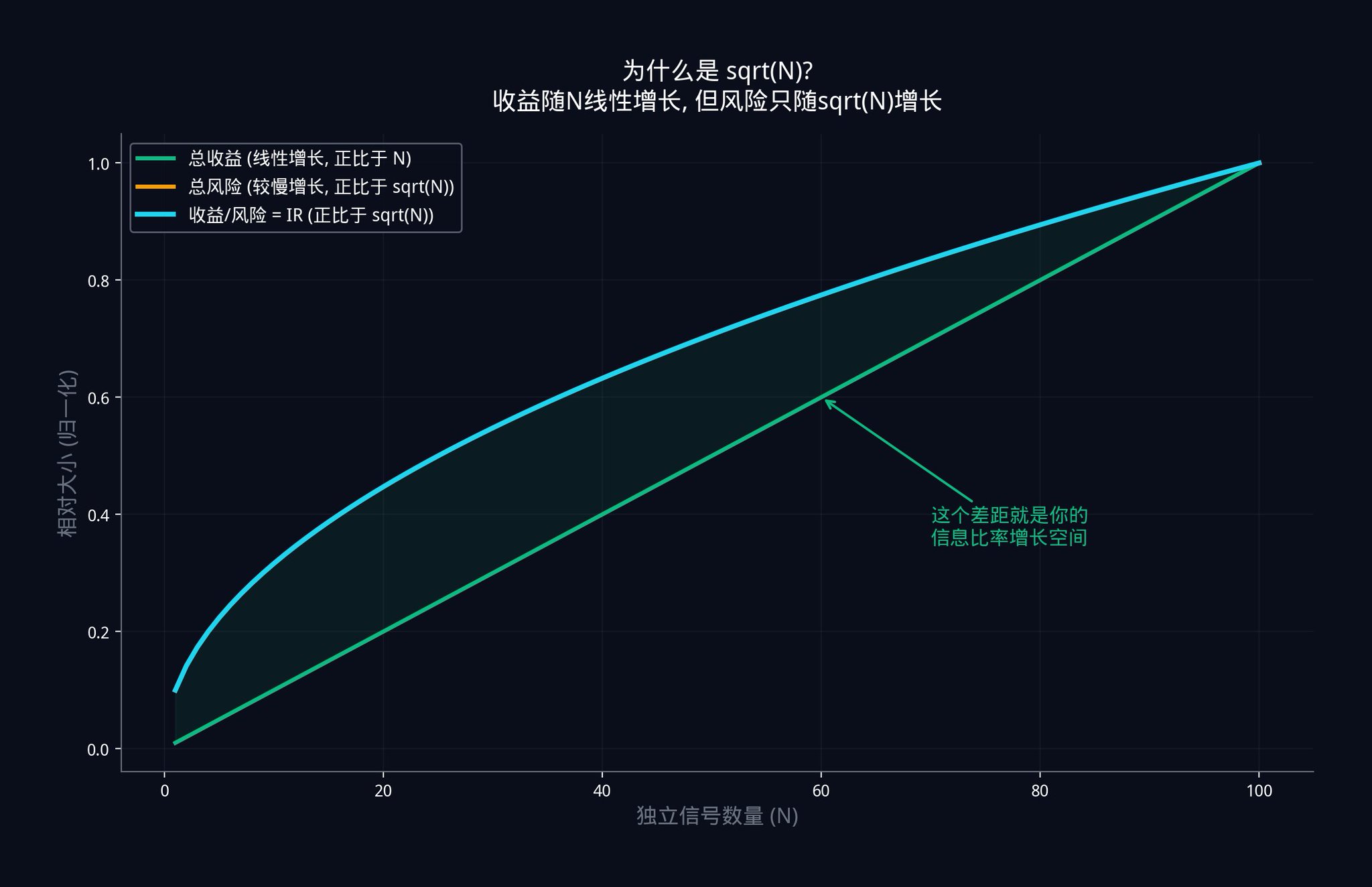
위의 그림은 이 관계를 보여줍니다. 녹색 선은 총 이익으로, 신호 수량에 따라 선형적으로 증가합니다. 파란색 선은 정보 비율 IR로, √N에 따라 증가합니다. 이익은 증가하지만 위험도 함께 증가하며, 이익이 위험보다 빠르게 증가합니다. 두 선 사이의 갭은 점점 커집니다. 이 갭은 독립적인 신호를 추가함으로써 얻는 거래 이점입니다.
구체적인 계산을 통해이 공식의 힘을 체감해 봅시다.
· 시나리오 A: 당신은 약한 신호 50개를 가지고 있습니다. 각 신호는 매우 약하며, IC는 0.05에 불과합니다. 그렇기 때문에 당신의 복합 시스템 IR은 0.05 x √50 = 0.05 x 7.07 = 0.354입니다.
· 시나리오 B: 다른 한 명의 트레이더는 강한 신호 1개를 가지고 있습니다. 그는 강력한 단일 신호를 찾기 위해 고군분투하여 IC가 0.10까지 올랐습니다(당신의 두배 정확도). 그러나 그는 단 하나의 신호만을 가지고 있기 때문에 그의 IR은 0.10 x √1 = 0.10입니다.
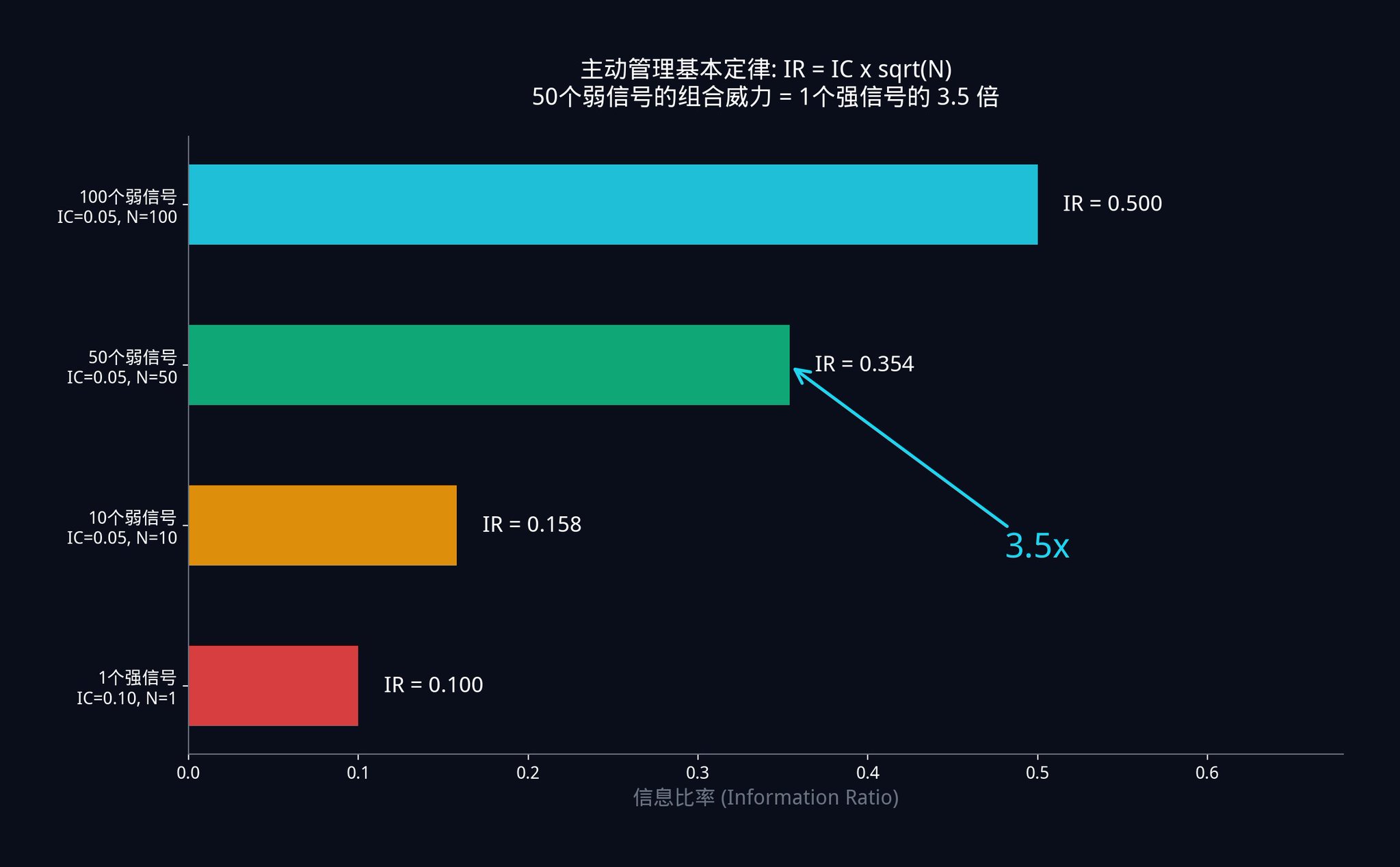
50개의 정확도가 절반만 되는 "쓰레기 신호"로 당신이 구성한 시스템의 성능은 그의 "신이신호"의 3.5배입니다.
이것이 헤지 펀드가 몇 백 명의 연구원을 고용하여 수백 개의 약한 신호를 발굴하는 데 마음을 쓰고, 모든 건을 "완벽한 지표"에 걸지 않는 이유입니다. 수학적으로 증명되었듯이, 완벽한 신호를 찾는 것은 막다른 길입니다.
올바른 방향은 다음과 같습니다: 가능한 한 많은 독립적인 약한 신호를 수집한 다음 수학을 사용하여 이를 결합합니다.
이 아이디어는 사실, insiders.bot 지갑 필터기를 개발할 때의 핵심 아이디어이기도 합니다. 사용자가 '완벽한 스마트 머니 지갑'을 찾는 대신, 사용자가 여러 가지 다른 전략을 동시에 추적하고 서로 다른 방향으로 보는 고 수익률 지갑 수백 개를 찾아 고 여기서 얻은 약한 신호를 중첩시켜야만 실제로 정확한 결론을 도출할 수 있습니다.
고급 연습 1:
현재 가장 의존하는 거래 신호를 정직하게 평가해보세요. 그 신호의 정보 계수(IC)는 얼마인가요? 만약 이를 체계적으로 측정해 본 적이 없다면, 당신은 항상 맹목적으로 행동해 왔다는 것을 의미합니다.
해보세요. Python을 사용하여 간단한 백테스트 스크립트를 작성하세요. 지난 30일간의 예측 순위와 실제 결과 순위를 기록한 다음 scipy.stats.spearmanr() 함수를 사용하여 자신의 IC를 계산하십시오. 결과에 놀랄지도 모릅니다.
확률 이론을 충분히 이해하고 싶다면 할바드 대학교의 무료 Introduction to Probability를 추천합니다. 앞 6 장만으로도 충분합니다.
신호를 결합해야 하는 이유를 이해한 후 다음 단계는 무엇인가요? 이러한 신호를 어디서 찾아야 하는지 알아보는 것입니다.
파트 2: 다섯 가지 신호 재료
첫 번째 파트에서는 신호가 무엇인지(가늠할 수 있고 방향성이 있으며 반복 가능한 데이터 포인트) 정의했습니다.
하지만 신호가 매우 강할 필요는 없습니다. 그것은 단지 대량의 관측 중에서 동전 던지기보다 약간 더 정확하게 행동하고 이러한 '약간 더 정확한' 행동이 안정적이고 검증 가능하다면 충분합니다.
그렇다면 기관들은 어디서 이러한 '약간 더 정확한' 데이터 포인트를 어디에서 찾을까요?
다음은 체계적 거래 팀이 실제로 사용하는 다섯 가지 핵심 신호 유형입니다.

2.1 가격 및 모멘텀 신호
모멘텀 신호는 최근 기간 동안 가격의 움직임과 속도를 살펴봅니다.
모멘텀 신호가 효과적인 이유는 시장 참가자들이 새로운 정보에 반응하는 데 관성이 있기 때문입니다.
· 단기 내에, 모두가 반응 속도가 충분하지 않아 추세가 지속됩니다.
· 중기, 모두가 다시 과도한 반응을 보이며 가격이 조정됩니다.
가속 중인 기차를 상상해보십시오. 기사가 가속을 멈추어도 기차는 즉시 멈추지 않습니다. 관성으로 인해 일정 거리를 계속 움직입니다. 동력 신호는 이러한 "관성 거리"를 캡처합니다.
Polymarket에서는 어떻게 사용합니까?
예를들어, 한 계약의 가격이 최근 3일 동안 $0.40에서 $0.55로 안정적으로 상승했으며 거래량도 동시에 확대되었습니다. 이는 지속적인 매수압력이 가격을 밀어올리고 있음을 나타냅니다.
가격이 단기적으로 계속 상승할 가능성이 높습니다. 이는 내부정보를 알고 있기 때문이 아니라, 시장의 관성이 아직 소진되지 않았기 때문입니다.
퀀트 연구에서 가장 기본적인 동력 공식은 과거 d 일의 평균 수익을 계산하는 것입니다: E(i) = (1/d) x Σ R(i,s)。여기서 d는 선택한 과거 일수이고, R(i,s)는 i 계약의 s일의 수익입니다.
2.2 평균 회귀 신호
평균 회귀 신호는 자산이 "합리적 가치"에서 얼마나 벗어났는지를 측정합니다.
핵심 로직은 다음과 같습니다: 관련 자산 간에는 가격 비율이 안정적이어야 합니다. 이러한 관계가 깨질 때, 회귀의 힘이 그것을 다시 끌어압니다.
Polymarket의 예를 들어보겠습니다. 두 개의 계약이 있다고 가정합시다: "트럼프 당선"과 "공화당 당선". 일반적으로 이 두 가지 확률은 긴밀하게 결합되어 있어야 합니다(트럼프가 공화당 후보이기 때문에). 만약 어느 날 "트럼프 당선"의 확률이 10% 급락했지만 "공화당 당선"의 확률은 2%만 떨어졌다면, 이는 강력한 평균 회귀 신호입니다. 시장이 가격 책정을 잘못하여 언젠가 다시 조정될 것입니다.
평균 회귀 신호는 고무줄과 같습니다. 늘어뜨릴수록 더 세게 튀어오릅니다. 그러나 유의해야 할 점은, 고무줄이 끊어질 수도 있다는 것입니다. 따라서 평균 회귀 신호는 개별적으로 의존하는 것이 아니라 다른 신호들과 함께 사용되어야 합니다.
2.3 변동성 신호
변동성 신호는 내재 변동성(시장 예상 변동폭)과 실현 변동성(실제 변동폭) 사이의 차이를 살펴봅니다.
왜 이런 격차가 생기는 걸까요? 그 이유는 판매 변동성을 감내하는 사람(예: 옵션을 판매하는 사람)들이 엄청난 tail risk를 감수하고 있기 때문입니다. 그들은 극단적인 상황을 커버하기 위해 추가 보상이 필요합니다. 이는 보험 회사가 항상 실제 보상 기대치보다 높은 보험료를 받는 것과 같습니다.
Polymarket에서 변동성 신호는 다음과 같이 이해할 수 있습니다: 한 계약의 가격이 $0.45에서 $0.55 사이에서 급격히 변동하지만 기본적인 상황에 실질적인 변화가 없는 경우(새로운 소식 없음, 정책 변화 없음), 그러한 "가짜 변동" 자체가 신호입니다. 이는 시장 참가자들이 공황 또는 흥분 상태에 있음을 알려주지만 이러한 감정은 종종 과도하며, 가격은 최종적으로 합리적 수준으로 돌아갈 것임을 보여줍니다.
2.4 요인 신호
요인 신호는 수십 년의 학술 연구를 통해 입증된 시스템적인 수익 초과입니다. 가장 유명한 다섯 가지 요인은 다음과 같습니다:
· 가치 (Value)
· 모멘텀 (Momentum)
· 저 변동성 (Low Volatility)
· 키포인트 (Carry)
· 퀄리티 (Quality)
각 요인은 시장이 위험을 가격 정할 때 인간 행동이나 시장 구조상의 지속적인 결함을 대표합니다.
예를 들어 "가치 요인"이 효과적인 이유는 인간들이 핫한 것을 추구하는 경향이 있기 때문입니다. 대중이 토론하는 계약들은 종종 이미 충분히 가격이 매겨져 있습니다. 반면 아무도 관심을 갖지 않는 "암묵적인 계약"은 가격 편향이 더 쉽게 존재하게 됩니다.
Polymarket에서는 작은 거래량을 갖는데 기초적으로 상황이 바뀐 계약들을 연구하는 데 더 많은 시간을 쏟아야 하며, 이미 몇 천 명이 지켜보는 핫한 핸들을 쫓기보다는 더 나은 가격 형성이 가능한 시장을 찾기 위해 insiders.bot의 홈페이지에서 변동성, 최신 시장, 거래량, 거래 참여자 수 등을 확인해야 합니다.
2.5 미시 구조 신호
미시 구조 신호는 고빈도 거래자들의 최애입니다. 이는 주문 대장의 심도 불균형, 매수-매도 스프레드의 동적 변화, 그리고 공격적인 거래량을 살펴봅니다.
이러한 신호들의 유효 시간은 매우 짧으며 보통 몇 분에서 몇 시간 사이입니다. 그러나 이러한 신호들은 당신에게 매우 중요한 사실을 알려줄 수 있습니다. 가격이 실제로 움직이기 전에 정보 우위를 가진 스마트 머니가 어디서 포지션을 잡고 있는지를.
미시 구조를 측정하는 가장 일반적인 지표 중 하나는 유효 스프레드(Effective Spread)입니다:
유효 스프레드 = 2 x |체결 가격 - 중간 가격|
유효 스프레드가 클수록 시장의 유동성이 나쁘며 거래 비용이 높아집니다. 유효 스프레드가 갑자기 확대될 때, 종종 정보를 가진 거래자가 진입하고 있음을 의미하며 메이커는 자신을 보호하기 위해 스프레드를 증폭시킵니다.
또 다른 중요한 지표는 VPIN(Volume-Synchronized Probability of Informed Trading, 거래량 동기화된 정보 거래 확률)입니다. 이 지표는 2012년에 Easley, Lopez de Prado, O'Hara 교수 3인이 제안했습니다. 이 지표는 매수와 매도 거래량의 불균형을 분석하여 시장에서 얼마나 많은 거래가 '정보를 가진 거래자'에 의해 이뤄지는지를 추정합니다.
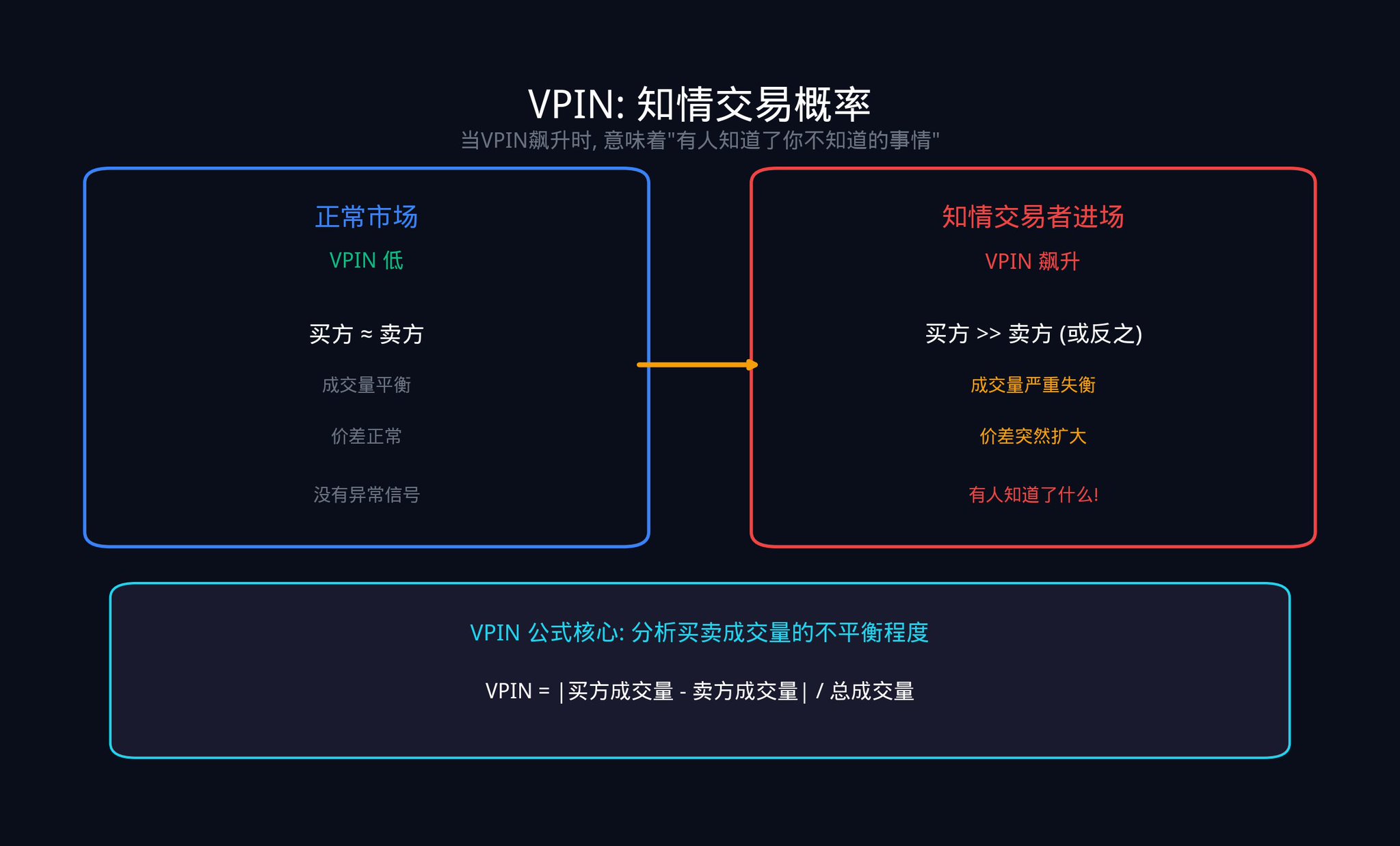
VPIN의 계산 논리는 사실 매우 직관적입니다. 거래량을 일정 크기의 '양동이'(예: 매 1000 거래마다 하나의 양동이)로 나눈 다음, 각 양동이에서 매수자 거래량과 매도자 거래량의 차이를 살펴봅니다. 차이가 크면 한 쪽이 일방적으로 돌격하고 있다는 것을 의미하며, 이는 일반적으로 정보를 가진 거래자가 활동 중임을 나타냅니다.
VPIN이 갑자기 급등할 때, 누군가가 당신이 모르는 정보를 알고 있다는 것을 의미합니다. 2010년 '플래시 크래시'(Flash Crash) 발생 직전 수 시간 동안 VPIN이 이미 예외적으로 증가하기 시작했습니다.
Polymarket에서는 스마트 머니의 On-Chain 활동이 가장 직접적인 미시 구조 신호입니다. 65% 이상의 승률을 가진 한 지갑이 어떤 계약에서 갑자기 대량 거래를 한 경우, 이는 매우 가치 있는 신호입니다.
우리는 insiders.bot의 스마트 머니 브라우저 및 v1.2/v1.3 신호에서 하는 일은 본질적으로 이러한 On-Chain 미시 구조 신호를 실시간으로 당신에게 전달하는 것입니다.
기억하세요, 이 다섯 가지 유형의 신호 중 어느 하나만으로는 체계적인 우위를 형성하는 데 충분하지 않습니다. 그들은 그저 원자재일 뿐입니다.
이제 우리는 최고 중요한 세 번째 부분으로 진입할 것입니다: 원자재를 황금으로 변환하는 "조합 엔진"입니다.
제3부: 11 단계 조합 엔진
이것은 전체 글에서 가장 핵심적인 부분입니다. 이 11단계는 기관이 일련의 원시 신호를 가장 우수한 가중치 조합으로 변환하는 데 사용하는 완전한 프로세스입니다.
이 11단계는 네 가지 단계로 분해할 수 있습니다: 데이터 준비, 시장 소음 제거, 독립적 이점 추출, 최적 가중치 할당
우선 배경을 다시 설명하면: N 개의 신호가 있다고 가정해 보겠습니다(예: 50개). 각 신호는 과거 일정 기간 동안 일련의 수익률 데이터을 생성했습니다(즉, 매일 얼마나 벌었거나 잃었는지).
이 조합 시스템이 할 일은 이러한 히스토리컬 데이터를 기반으로 각 신호에 얼마의 자금 가중치를 할당할지 계산하는 것입니다.
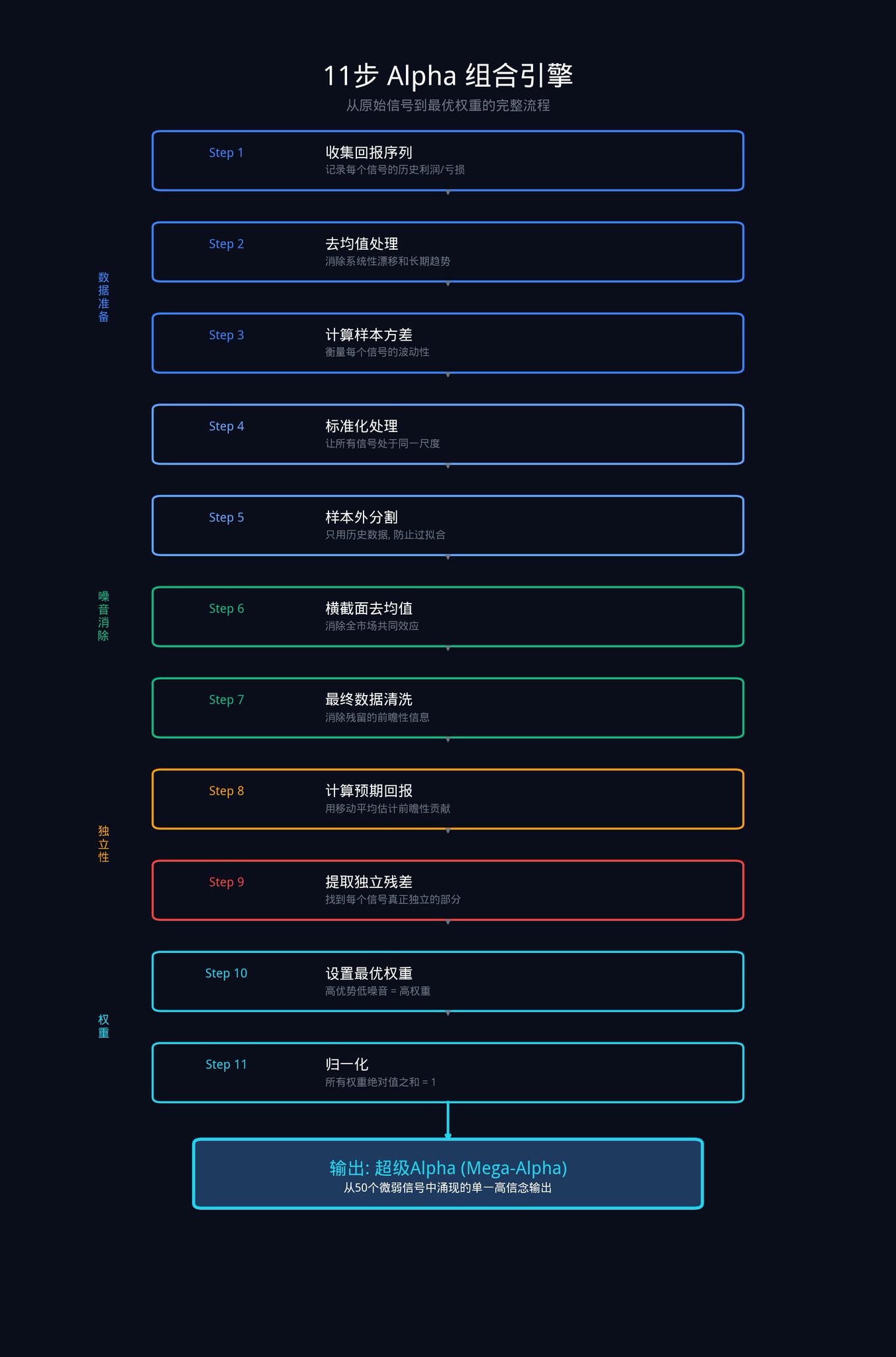
단계 1: 데이터 준비
이 단계의 목표는 모든 신호가 동일한 기준선에 서 있도록 하는 것입니다.
단계 1: 각 신호의 히스토리컬 성과 수집
이것은 가장 기본적인 단계입니다. 각 신호가 과거 각 시간대별로 얼마나 실제 수익을 올렸는지 또는 손해를 봤는지를 기록해야 합니다.
예를 들어, 모멘텀 신호가 지난 30일 동안 첫째 날에 2%를 벌었고, 둘째 날에 1%를 잃었고, 셋째 날에 0.5%를 벌었다면... 이러한 데이터를 모두 기록해야 합니다. 각 신호에는 이러한 데이터 열이 있어야 합니다.
수학적 용어로 표현하면, 각 신호 i의 각 시간대 s의 수익률 R(i,s)을 수집합니다.
단계 2: 시스템적 이동평균 제거(평균 제거)
각 신호의 히스토리컬 수익률에서 해당 신호의 평균 수익률을 뺍니다.
이렇게 하는 이유는 무엇입니까?
예를 들어,
- "저가매수" 신호가 있다고 가정해 보겠습니다. 최근 1년 동안 암호화폐 시장 전체가 대폭 상승했기 때문에 이 신호는 큰 돈을 벌어보인다고 합니다.
· 그러나 이것이 정말 신호의 공로인가요? 그렇지 않을 수도 있습니다. 어떤 랜덤한 전략으로 바꿔도, 매수 시장에서는 돈을 벌 수 있습니다. 평균값을 뺀 후에야 이 신호가 「시장 전체 트렌드를 배제한」 후에, 정말로 예측 능력이 있는지를 볼 수 있습니다.
구체적인 공식: X(i,s) = R(i,s) - mean(R(i))。
단계 3: 각 신호의 변동률 계산
이 단계는 각 신호의 수익이 얼마나 변동성이 있는지를 측정합니다.
· 어떤 신호는 평균적으로 매일 0.1%를 벌지만 때로는 5%를 벌기도 하고 4%를 잃기도 합니다.
· 다른 신호는 평균적으로 매일 0.1%를 벌지만 변동 범위는 -0.5%부터 +0.7% 사이에 머무릅니다.
· 두 신호의 평균 수익은 같지만, 두 번째 신호가 분명히 더「안정적」이고 더 신뢰할 만합니다.
변동률은 이러한「안정성」을 측정하는 데 사용됩니다.
구체적인 공식:σ(i)² = (1/M) x Σ X(i,s)²。
단계 4: 표준화 처리
단계 2의 결과를 단계 3의 변동률로 나눕니다.
왜 이 단계가 필요한가요? 다른 신호의 「단위」가 다르기 때문입니다. 모멘텀 신호는 백분율로 계산될 수 있고, 미시 구조 신호는 베이시스 포인트(0.01%)로 계산될 수 있으며, 변동률 신호는 절대 숫자로 계산될 수 있습니다. 이러한 값을 직접 비교하면 사과와 오렌지를 비교하는 것과 같아 전혀 의미가 없습니다.
표준화하면, 모든 신호가 동일한 척도로 조정됩니다. 달러, 유로, 엔을 모두 같은 통화로 환산하는 것과 같습니다. 이렇게 하지 않으면 공평하게 비교할 수 없습니다.
구체적인 공식:Y(i,s) = X(i,s) / σ(i)。
단계 2: 시장 소음 제거
이 단계의 목표는 각 시그널의 성능에서 "시장 전체의 상승 및 하락"을 제거하고 시그널 자체의 실제 능력만을 남기는 것입니다.
단계 5: 샘플 외 분할
가중치를 계산할 때는 과거 데이터만 사용하고 최근의 관측치는 버립니다.
이 단계는 "과적합(Overfitting)"을 방지하기 위한 것입니다.
과적합이란 무엇인가요? 예를 들어보겠습니다. 한 학생이 지난 10년간의 시험 문제를 모두 외워서 모의고사마다 만점을 받았습니다. 하지만 본 시험에서는 새로운 문제가 나와서 하나도 못 푸는 상황입니다. 그 학생은 "지식을 이해하는 것"이 아니라 "답을 외우는 것"입니다.
양자화 거래에서는, 과적합은 더 큰 문제입니다. 당신의 모델은 과거 데이터에서 완벽한 성능을 보일 수 있지만, 실거래에서 실패할 수 있습니다. 샘플 외 분할은 당신의 모델이 "규칙을 학습하는 것"이며 "과거를 기억하는 것"이 아님을 보장합니다.
구체적인 방법은 다음과 같습니다:
데이터를 두 부분으로 나눕니다.
· 모델을 훈련하기 위해 데이터의 처음 80%를 사용합니다(가중치 계산),
· 모델이 실제로 효과적인지 확인하기 위해 나머지 20%의 데이터를 사용합니다.
· 모델이 나머지 20%의 데이터에서도 수익을 창출하면, 그것은 진정한 규칙을 학습했다는 것입니다.
단계 6: 단면 평균 제거 (Cross-sectional Demeaning)
각 시간 지점에서 각 시그널의 성능을 그 시간 지점에서의 모든 시그널의 평균 성능을 빼줍니다.
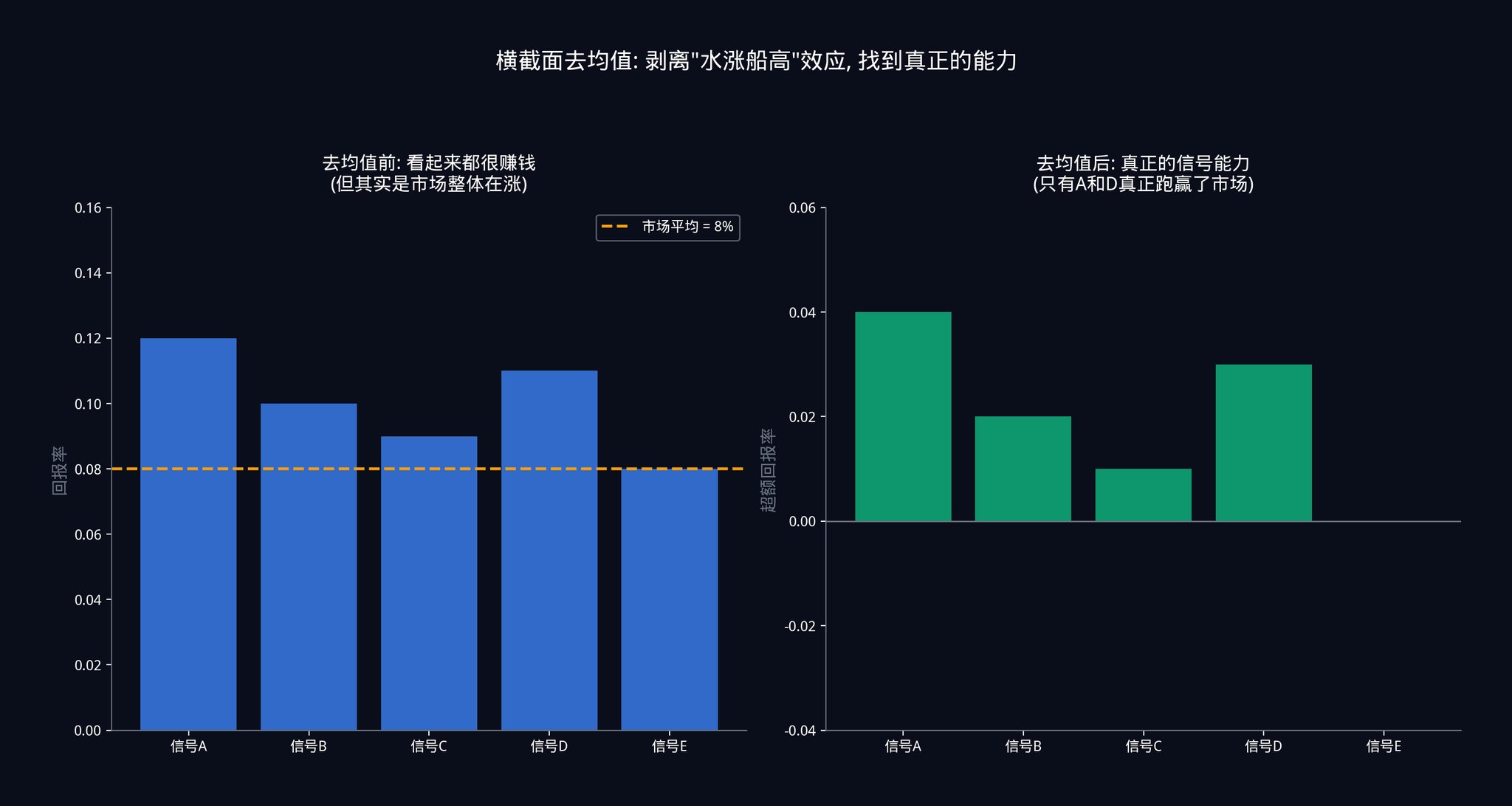
이 단계는 매우 중요합니다. 여기서 특정 시나리오를 통해 설명하겠습니다.
가령, 오늘 미국 연방준비제도가 금리 인하를 발표했습니다. 전체 시장이 급등했습니다. 여러분의 50개 시그널이 모두 "매수" 신호를 보냈을지도 모르며, 각 시그널은 모두 돈을 벌었을 것입니다.
만약 단면 평균 제거를 수행하지 않는다면, 당신은 이 50개 시그널이 모두 정확하다고 생각할 것입니다. 그러나 실제로는 이것은 "물의물 증세" 효과입니다. 시장 전체가 상승하고 있어서 여러분의 시그널은 무슨 예측을 하든 돈을 벌게 될 것입니다. 이것은 시그널의 능력이 아니라 시장의 은혜입니다.
모든 신호의 평균 성능을 뺀 후에야 진실을 볼 수 있습니다: 모두가 돈을 벌고 있는 날에, 어떤 신호가 다른 사람보다 더 많이 벌었는지? 모두가 돈을 잃고 있는 날에, 어떤 신호가 다른 사람보다 더 적게 잃었는지? 이러한 "상대적 성과"가 바로 신호의 진정한 능력입니다.
보다 구체적으로 말하면: Λ(i,s) = Y(i,s) - (1/N) x Σ Y(j,s)。
*참고: 2단계의 "평균 제거"와 6단계의 "단면 평균 제거"는 다릅니다. 2단계는 각 신호의 시계열에 대해 평균을 제거하는 것입니다(장기적인 추세 제거). 6단계는 각 시간 단계에서 모든 신호 간의 평균을 제거하는 것입니다(시장 전체 효과 제거). 둘 다 필수적입니다.
단계 7: 최종 데이터 정리
이것은 최종 데이터 정리 단계입니다. 이는 데이터 시퀀스에서 "선행 정보"가 남아있지 않도록 합니다.
선행 정보란 무엇인가요? 즉, 당신이 결정을 내리는 그 시점에서 앞으로 발생할 데이터를 미리 알 수 없는 정보를 말합니다. 예를 들어, 월요일에 금요일의 종가를 사용하여 결정을 내릴 수 없습니다. 이는 상식적으로 들리지만, 복잡한 데이터 처리 과정에서 이러한 "데이터 유출"이 생각보다 쉽게 발생할 수 있습니다.
단계 삼: 독립적인 우위 추출
이 단계는 전체 엔진의 핵심입니다. 이를 수행해야 할 작업은: 각 신호로부터 해당 고유한 예측 능력을 추출하여, 다른 신호와 중복되는 부분을 제거하는 것입니다.
단계 8: 예상 수익률 계산
이동 평균을 사용하여, 각 신호의 미래 예상 기여도를 계산합니다.
구체적으로 말하면, 각 신호의 최근 d일 수익률의 평균을 해당 신호의 미래 성능 예측으로 삼습니다. 그런 다음 이 예측 값을 정규화합니다(변동성으로 나눔) 수 있도록하여 서로 다른 신호의 예상 수익률을 직접 비교할 수 있게 합니다.
공식적으로:
· E(i) = (1/d) x Σ R(i,s)
· E_norm(i) = E(i) / σ(i)。
단계 9: 독립적인 잔차 추출(Othogonalization, 직교화)
이것은 전체 11단계 중에서 가장 중요한 단계입니다.
당신이 두 가지 신호를 가지고 있다고 가정해 봅시다.
· 신호 A는 "날씨 예보 보기"입니다.
· 신호 B는 "보행자가 우산을 가지고 있는지 확인"입니다.
이 두 신호 모두 오늘 비가 오는지를 예측할 수 있습니다.
그러나 문제는 보행자가 우산을 챙기는 것이 아마도 날씨 예보를 확인했기 때문이라는 것입니다. 따라서 신호 A와 신호 B 사이에는 많은 정보 중복이 있습니다. 만약 이 두 신호를 동시에 사용한다면, 당신은 두 개의 독립적인 신호를 갖고 있다고 생각할지 모르지만 사실은 하나의 신호(날씨 예보)가 두 번 표현된 것뿐입니다.
9단계가 하는 일은 바로 이러한 정보 중복을 제거하는 것입니다.
구체적으로 어떻게 할까요? 각 신호의 예상 수익 E_norm(i)에 대해 모든 다른 신호의 과거 데이터 Λ(i,s)에 대한 회귀 분석을 수행합니다. 회귀 분석이란: 다른 신호를 사용하여 이 신호를 "설명"하는 것입니다. 설명할 수 있는 부분은 중복된 부분이므로 제거됩니다. 설명할 수 없는 부분은 이 신호의 고유한 기여도이므로 유지됩니다.
이 "설명할 수 없는 부분"은 수학적으로 잔차(Residual)라고 하며 ε(i)로 표시됩니다.
만약 선형 대수를 공부한 적이 있다면, 이것은 그람-슈미트 직교화의 응용 중 하나입니다. 공부한 적이 없어도 괜찮습니다. 기억해야 할 한 가지는 다음과 같습니다: 9단계는 각 신호의 참으로 고유하고 대체불가능한 예측 능력 부분을 찾는 것입니다.
단계 네: 최적 가중치 할당
10단계: 최적 가중치 설정
가중치 계산 공식은: w(i) = η x ε(i) / σ(i)입니다.
이 공식은 이렇게 말합니다: 각 신호의 가중치는 그 독립적인 기여도 ε(i) (9단계에서 얻은)를 그 신호의 변동성 σ(i) (3단계에서 얻은)로 나눈 후에 스케일링 계수 η를 곱한 것입니다.
이것이 의미하는 바는 무엇일까요? 엔진은 자동으로 "고유한 기여도가 크고" "안정적인 성과"를 보이는 신호에 더 높은 가중치를 할당할 것입니다. 그리고 "잡음이 큰" 또는 "모방만 하는" 신호는 자동으로 가중치가 낮아질 것입니다.
모든 것이 수학적으로 자동으로 이루어지며 주관적인 판단이 필요하지 않습니다. '이 신호가 몇 비율을 차지해야 하는지'를 감각적으로 결정할 필요가 없습니다. 공식이 최적의 답변을 알려줍니다.
단계 11: 정규화
마지막 단계는 스케일링 계수 η를 조정하여 모든 가중치의 절대값 합이 1이 되도록 하는 것입니다.
이렇게 함으로써 총 자금 할당이 100%이며 무의식 중에 레버리지가 증가하지 않습니다. 이 단계를 수행하지 않으면 가중치의 총합이 150%인 것을 발견할 수 있으며, 이는 1.5배 레버리지 거래를 하고 있다는 것을 의미하며 본인은 전혀 인지하지 못한 채일 수 있습니다.
수학적으로 말하면: η를 설정하여 Σ|w(i)| = 1이 됩니다.
이 11단계의 최종 출력은 N개의 신호 중 각각의 최적 가중치입니다. 이러한 약한 신호들을 가중치에 따라 조합하면 슈퍼 알파(메가 알파)를 얻게 됩니다. 고승률, 고신념의 단일 출력입니다.
심화 연습 2:
현재 신호 스택에서 이 프로그램을 실행하면 어떤 신호가 높은 가중치를 받았고 어떤 것이 낮은 가중치를 받았는지 놀라게 될까요? 답변은 현재 실행 중인 것에 대한 독립적인 구조 이해 수준을 보여줍니다.
이 행렬 연산 논리를 깊이 이해하려면 MIT의 무료 공개 강의인 Linear Algebra의 직교화 섹션을 권장합니다. Gilbert Strang 교수님의 설명은 매우 명확합니다.
파트 4: 독립성 함정
포트폴리오 엔진은 한 가지 문제를 해결합니다. 이 문제는 개별 신호를 볼 때는 감춰져 있지만 수학을 이해하면 어디에나 존재합니다.
첫 번째 부분에서 언급한 액티브 매니지먼트의 기본 법칙으로 돌아가 봅시다:
IR = IC x √N
이 세 글자가 무엇을 나타내는지 기억하시나요? IR은 전체 시스템의 '리스크 조정 수익률'입니다(즉, 전략이 얼마나 안정적인지를 나타냅니다). IC는 개별 신호의 평균 정확도입니다. N은 포트폴리오의 독립적인 신호 수입니다.
지금 강조할 키워드 하나가 있습니다: 독립성.
여기서의 N은 여러분의 시그널 스택에서의 총 시그널 수가 아닙니다. 이것은 유효한 독립적인 시그널의 수입니다. 이 두 숫자는 매우 다를 수 있습니다.
왜냐하면 시그널들은 서로 "몰래" 상호 연관될 수 있기 때문입니다.
모멘텀 시그널과 평균회귀 시그널은 본질적으로 완전히 다른 것으로 보입니다 (하나는 추세를 따르고, 다른 하나는 평균으로 회귀합니다). 그러나 어떤 시장 환경에서는 두 시그널이 동시에, 같은 방향으로 같은 매크로 경제 뉴스에 반응할 수 있습니다.
· 예를 들어, 미 연방준비제도가 갑자기 금리를 인상하면, 모멘텀 시그널은 "추세 하락, 매도"라고 하고, 평균회귀 시그널도 "평균회귀가 너무 멀어졌지만 방향은 역시 아래"라고 합니다.
· 이 순간에, 두 가지 서로 독립적으로 보이는 시그널이 실제로는 같은 관점을 표현하고 있습니다.
당신이 그들에게 동등한 가중치를 부여한다면, 당신은 두 독립적인 관점 사이에 리스크를 분산하고 있다고 생각할 것입니다. 그러나 실제로는, 당신은 같은 관점에 두 배의 위치를 취하고 있는 것입니다.

이것이 왜 제 3부에서 6단계 (스냅샷에서 평균을 뺌, 즉 모든 시그널의 평균 성과를 각 시간 단위에서 제거하여 "물이 일렁이는 효과"를 제거)와 9단계 (독립적인 잔차 추출, 즉 회귀 분석을 통해 시그널 간의 정보 중첩을 제거하고 각 시그널의 고유한 기여만 남김)가 그토록 중요한 이유입니다. 이들의 역할은 시그널 사이에 숨겨진 공유 구성 요소를 식별하고 제거하는 것입니다.
50개의 관련된 시그널을 실행한다 해도, 이것은 실제로 10개에서 15개의 독립 시그널에 대한 분산 효과만을 가져다줄 수 있습니다. 당신의 시그널이 실제로 진정한 독립적인 정보 원천에 기초하고 있고 올바르게 조합 엔진이 작동한다면, 당신은 50개 시그널의 모든 이점을 얻을 수 있습니다.
실제 운영에서 이것은 무엇을 의미합니까?
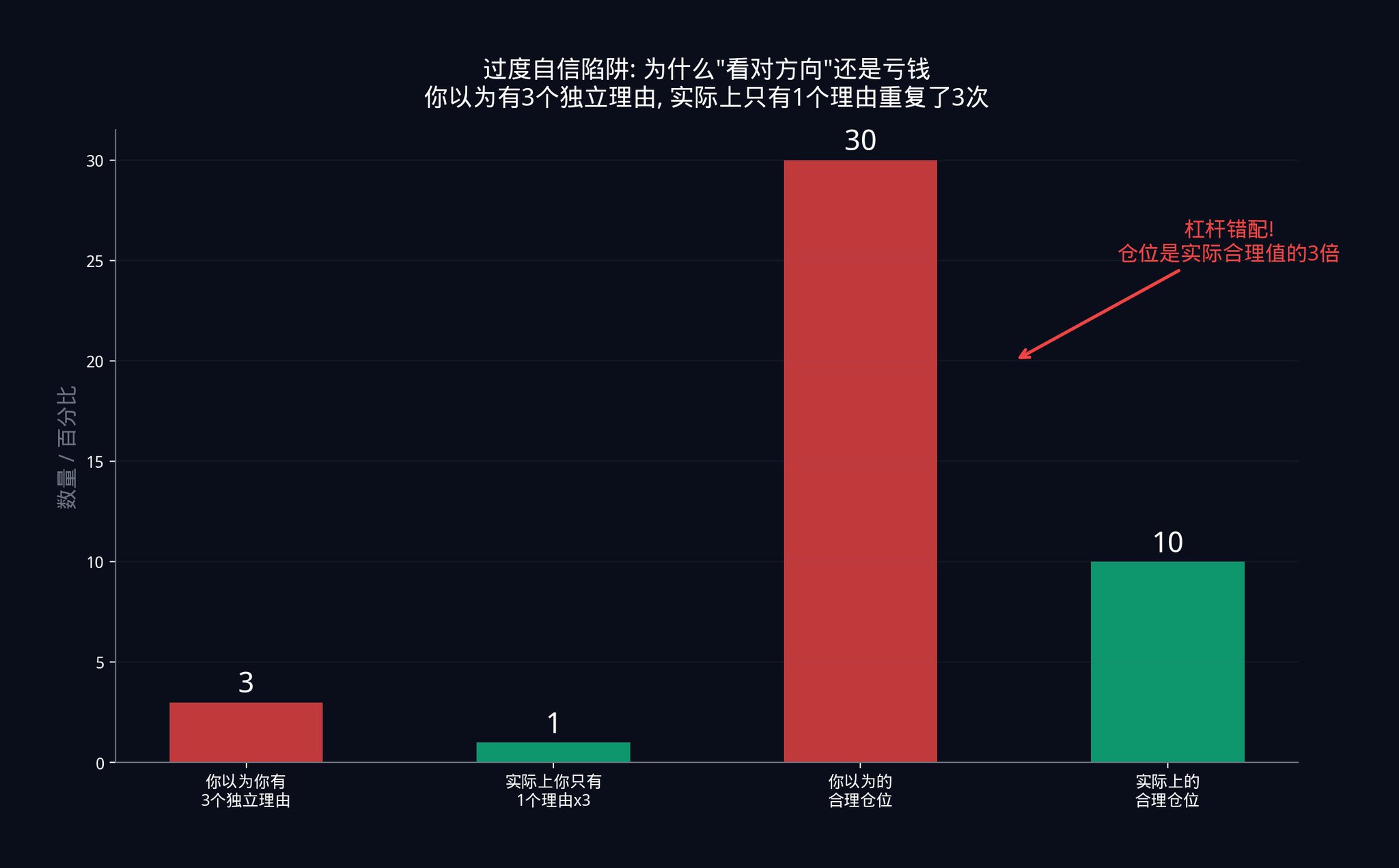
· 거래자가 20개의 독립 시그널을 실행하고 있다고 가정해 봅시다. 그는 거래 규모를 20개의 독립 시그널에 따라 계산하고 있습니다. 그러나 실제로는 시그널 간에 숨겨진 상관 관계로 인해, 그는 6개의 유효한 독립 시그널만 가지고 있습니다.
· 20개의 독립 시그널을 지지하는 거래 규모는 6개의 시그널에 대해 너무 큽니다. 얼마나 큰가요? 20/6 ≈ 3.3배 큽니다. 그의 실제 레버리지는 그가 생각한 것보다 3배 가량 더 큽니다.
이러한 레버리지 불일치는 대부분의 시스템 트레이딩 청산의 실제 원인입니다. 트레이더는 방향에 대해 옳았지만 규모에 대해서는 틀렸습니다. 시장이 상승할 것이라는 것은 맞지만, 그가 한 사이즈가 너무 컸습니다. 정상적인 조정만으로도 그를 청산시킬 수 있었습니다.
포트폴리오 엔진은 정직한 회계를 강요합니다. 당신을 속이지 않습니다. 그것은 당신에게 당신의 신호 스택이 실제로 독립적인 구조를 가지고 있는지를 알려줄 것입니다. 그런 다음 실제 상황에 따라 가중치를 할당하게 됩니다. 여기서 당신이 생각한 것에 따라 할당하는 것이 아닙니다.
올바른 거래 분석에서 계속 손실을 보는 트레이더들은 거의 항상 측정하지 않은 상관 관계에서 지는 경우가 많습니다. 그들은 자신이 독립적인 세 가지 이유를 가지고 있다고 생각합니다. 실제로는 그들이 한 가지 이유만 세 번 표현한 것입니다. 그리고 포지션은 세 가지 이유에 따라 설정되었습니다.
포트폴리오 엔진은 이러한 실패 패턴을 구조적으로 제거합니다.
심화 연습 3:
현재 사용 중인 모든 신호를 가져와 두 가지씩 매칭하여 상관 계수를 계산하십시오. 넘파이의 corrcoef() 함수를 사용할 수 있습니다. 만약 어떤 신호 쌍의 상관 관계가 0.5를 초과한다면, 그들은 수학적으로 독립적이지 않습니다. 당신은 당신의 신호 스택을 다시 검토해야 합니다.
Marcos Lopez de Prado의 Advances in Financial Machine Learning을 추천합니다. 특히 피처 중요성 및 직교화에 관한 장을 읽어보세요. 이 책은 현대 양자적 방법의 필독서입니다.
제5 부문: Polymarket에 적용
처음 네 부분의 내용은 주식 및 다자산 시스템 트레이딩의 맥락에서 구축되었습니다. 좋은 소식은, 이러한 수학 모델을 직접 예측 시장으로 이전할 수 있다는 것입니다. 단지 하나의 대체가 필요합니다: 당신이 "예상 수익"에 대한 조합이 아니라 "예상 확률"에 대한 신호를 조합하고자 하는 것입니다.
예측시장에서 각 신호가 생산하는 것은 수익을 추정하는 것이 아니라 내재된 확률을 추정하는 것입니다.
5.1 다섯 가지 확률 신호
첫째, 크로스 플랫폼 가격 신호: 만약 Polymarket의 어떤 계약의 YES 가격이 $0.45이지만, Betfair에서 동일한 이벤트에 대한 배당률이 52%를 시사한다면, 이 7% 포인트의 가격 차이가 당신의 신호입니다. 두 개의 플랫폼이 동일한 이벤트에 대해 서로 다른 가격을 지정하면, 적어도 하나는 틀렸습니다.
두 번째, 교정 신호: 40 억 건의 Polymarket 거래 기록을 조사한 결과, 시스템적인 편향을 발견했습니다: 가격이 5%에서 15% 범위에 있는 계약의 경우, 최종 해결이 YES로 이뤄지는 비율은 4%에서 9%에 불과했습니다. 이는 시장이 낮은 확률 이벤트 발생 가능성을 시스템적으로 과대평가했음을 의미합니다. 이 편향은 안정적이고 반복 가능하므로 유효한 신호입니다.
세 번째, 베이즈 업데이트 신호: 이것은 양자화 거래의 핵심 도구입니다. 이것이 대답하는 핵심 질문은: 새로운 데이터를 획득했을 때 기존의 믿음을 어떻게 정확하게 업데이트해야 하는가?
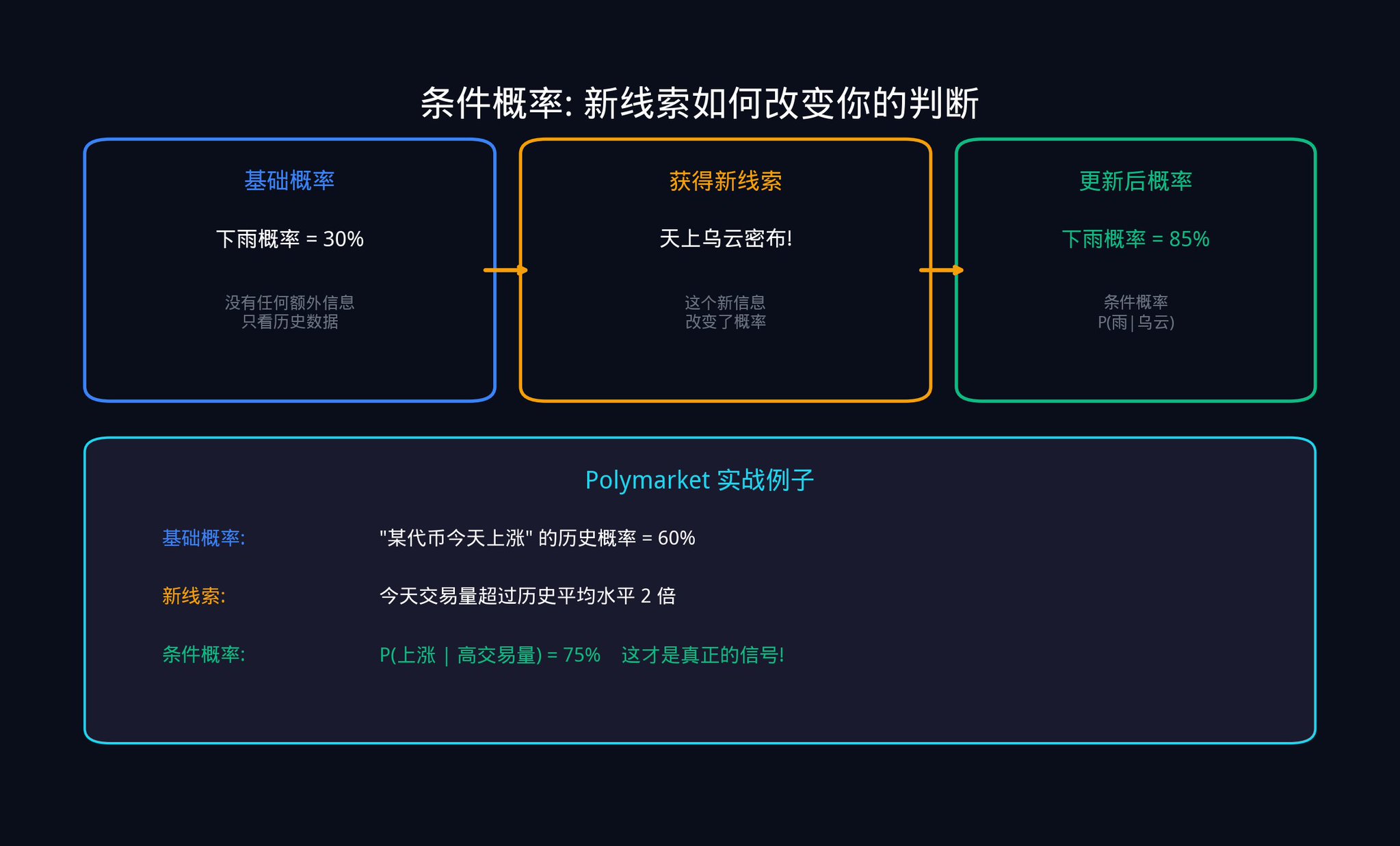
베이즈 업데이트를 설명하기 위해 구체적인 예시를 들어보겠습니다.
다음과 같은 Polymarket 계약에 주목하고 있다고 상상해보십시오: "이번 달에 특정 국가의 법안이 통과될 것인가?". 현재 시장 가격은 $0.40으로, 시장은 통과될 확률이 40%라고 생각하고 있습니다. 이것이 여러분의 사전확률(Prior)입니다.
갑자기, 한 가지 뉴스가 나왔습니다: 그 법안이 핵심 상원의원으로부터 공개 지지를 받았다는 소식입니다.
여러분은 확률을 직접 80%로 변경할 수 없습니다. 정확한 계산을 위해 베이즈 공식을 사용해야 합니다.
베이즈 공식은 다음과 같습니다:
P(통과|지지) = P(지지|통과) x P(통과) / P(지지)
간단히 말하면:
"해당 상원의원의 공개 지지가 알려진 상태에서, 법안이 통과될 확률" = "만약 법안이 실제로 통과된다면, 그 상원의원이 공개 지지할 확률" x "법안이 통과될 사전 확률" / "해당 상원의원이 공개 지지할 총 확률"
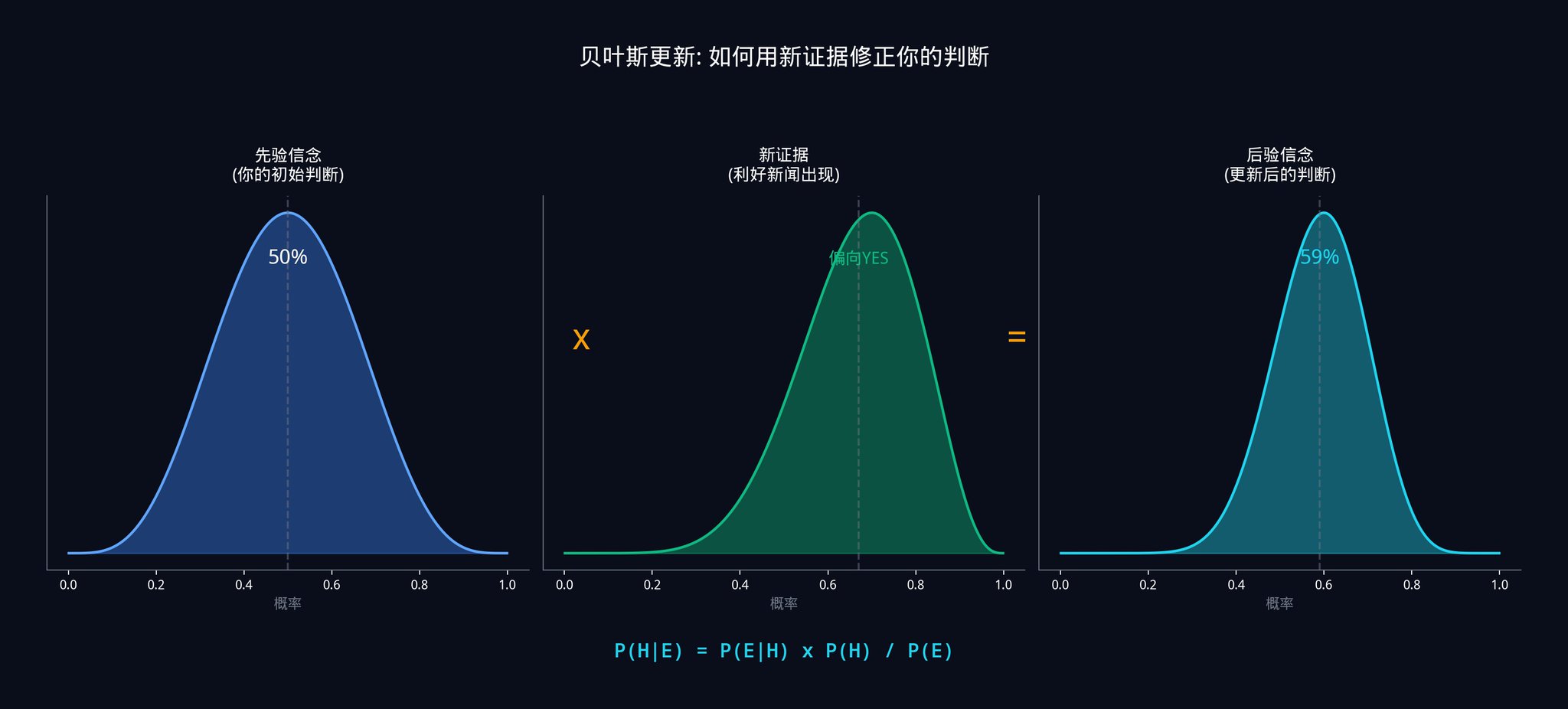
여러분이 추정한 것을 바탕으로:
· 법안이 실제로 통과된다면, 그 상원의원이 공개 지지할 확률은 80%입니다 (일반적으로 확실한 경우에만 발언하기 때문)
· 법안이 통과되지 않는다면, 그 상원의원이 공개 지지할 확률은 20%입니다 (가끔 실수를 저지를 때도 있기 때문)
· 법안이 통과될 사전 확률은 40%입니다
· P(지지) = 0.80 x 0.40 + 0.20 x 0.60 = 0.32 + 0.12 = 0.44
· P(통과|지지) = 0.80 x 0.40 / 0.44 = 0.32 / 0.44 = 72.7%
그래서 이 뉴스를 보고 나면, 당신은 법안이 통과될 확률을 40%에서 72.7%로 업데이트해야 합니다. 시장 가격이 여전히 $0.50에 머물러 있다면, 여러분은 22.7%의 이점을 얻게 됩니다.
베이즈 업데이트의 핵심은, 여러분이 새로운 확률을 "추측"하는 것이 아니라, 수학적으로 정확하게 계산하는 것입니다. 여러분의 각 판단에는 근거가 있습니다.
네 번째, 미시 구조 신호: VPIN을 활용하여 (우리가 두 번째 부분에서 다뤘던 "알고있는 거래자 확률" 지표이며, 매수 및 매도 거래량의 불균형을 분석하여 알고있는 거래자의 활동 여부를 평가함) 및 유효 스프레드를 사용하여, 알고 있는 주문 흐름의 방향에 대한 확률을 암시합니다.
다섯 번째, 모멘텀 신호: 결제가 곧 이루어질 때의 계약 가격 변동 속도와 방향에 따라 확률을 암시합니다.
5.2 신호로부터 베팅까지: 전체 과정
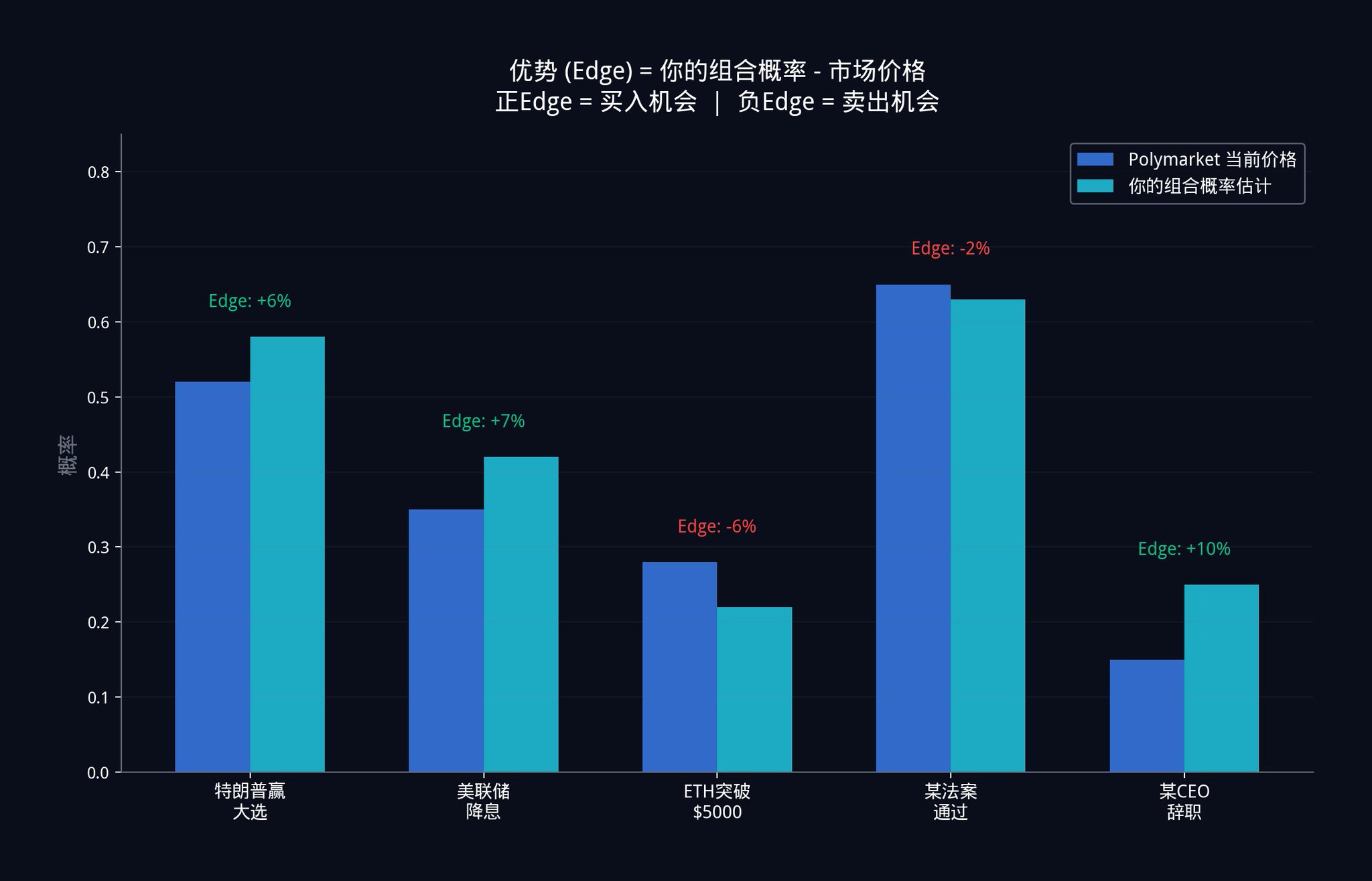
이러한 내재 확률 추정치를 각각 사용하여, 11단계 설명된 조합 엔진을 완벽하게 실행합니다. 결과는 단일 가중치 조합 확률 추정치입니다. 이 추정치는 각 신호의 독립적인 기여에 따라 가중치가 최적으로 할당됩니다(제 9단계의 직교화를 기억하십니까? 신호 간의 정보 중첩을 제거하고 고유한 부분만 유지함).
그 조합 추정치와 현재 Polymarket 가격 사이의 차이가 여러분의 이점(Edge)입니다.
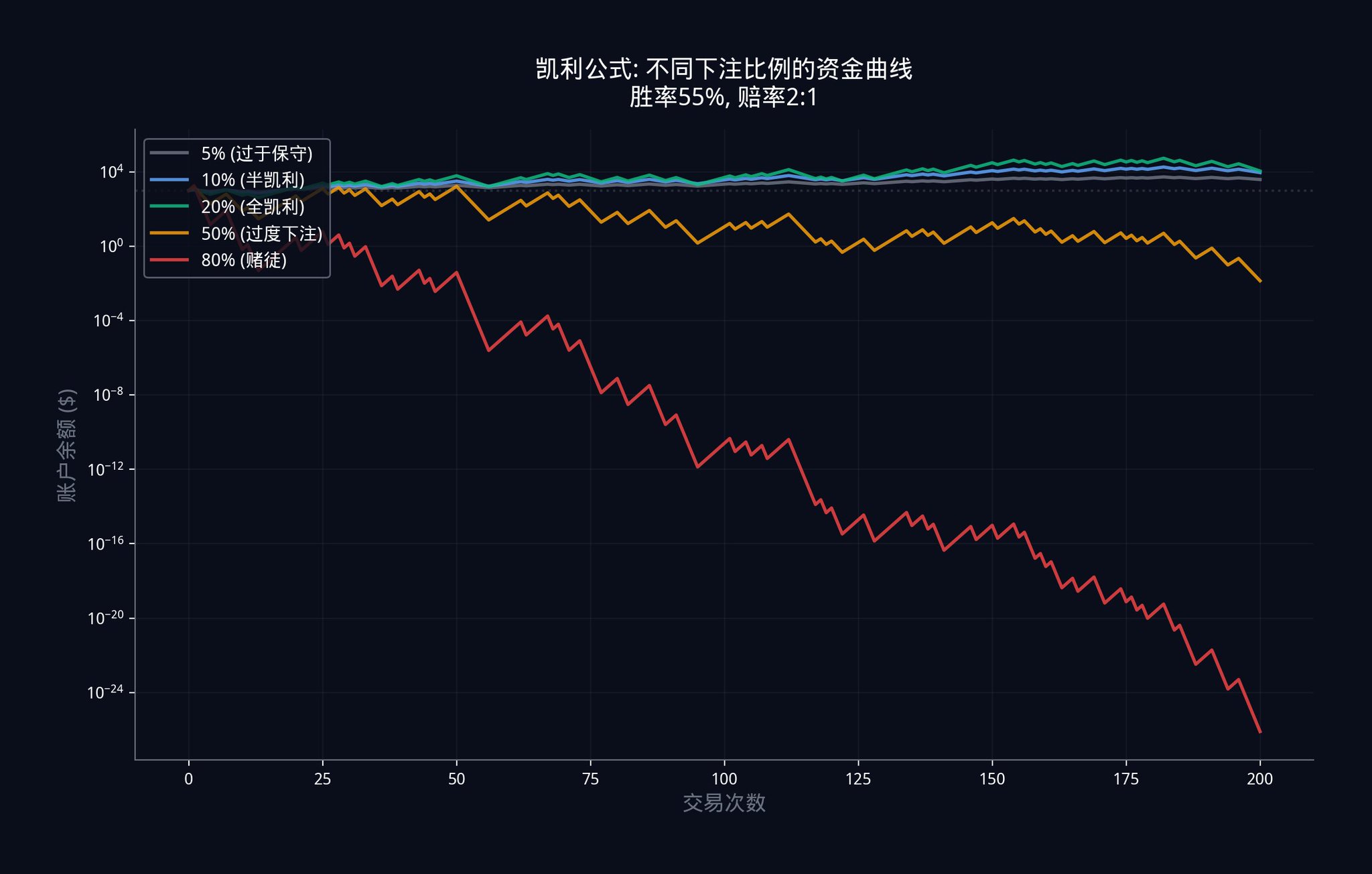
5.3 켈리 공식: 얼마를 베팅해야 할까요?
이점을 확보한 후, 가장 중요한 질문이 제기됩니다: 얼마나 베팅해야 할까요?
너무 적게 베팅하면 이점을 낭비하고 이윤을 충분히 얻지 못합니다. 너무 많이 베팅하면 한 번의 오진으로 처음으로 돌아갈 수도 있습니다.
기관은 켈리 공식을 사용합니다. 표준 켈리 공식은 다음과 같습니다:
f_kelly = (p x b - q) / b
여기서 p는 당신이 예측한 승률(귀하의 조합 확률)이고, q = 1 - p는 패배율, b는 배당률입니다.
Polymarket에서는 배당률 b를 직접 가격에서 계산할 수 있습니다: b = (1 / 시장 가격) - 1입니다. 예를 들어 시장 가격이 $0.40이라면, 배당률 b = (1/0.40) - 1 = 1.5입니다.
귀하의 조합 모델이 실제 확률이 60%라고 알려주었고 (즉, p = 0.60), 그리고 시장 가격이 $0.40 (배당률 b = 1.5)이라고 가정해 봅시다. 이러한 상황에서 표준 켈리는 귀하에게 베팅할 것을 권장합니다:
f_kelly = (0.60 x 1.5 - 0.40) / 1.5 = (0.90 - 0.40) / 1.5 = 0.50 / 1.5 = 33.3%의 자금.
그러나 표준 켈리에는 치명적인 가정이 있습니다: 당신의 승률 추정이 100% 정확하다고 가정합니다. 현실에서는 당신의 추정이 항상 오차가 있을 수 있습니다. 그래서 기관들은 경험 켈리 공식을 사용하며, 이 공식은 "불확실성 패널티"를 추가합니다.
f_empirical = f_kelly x (1 - CV_edge)
여기서 CV_edge는 귀하의 강세 추정의 변이 계수(Coefficient of Variation)입니다. 이는 귀하의 추정이 얼마나 불확실한지를 측정합니다. CV_edge가 클수록 불확실성이 크며, 공식은 자동으로 베팅 금액을 줄입니다.
CV_edge를 어떻게 계산합니까? 몬테카를로 시뮬레이션을 사용할 수 있습니다. 간단히 말해, 귀하의 모델을 수천 번 실행하여 강세 추정이 다양한 시나리오에서 어떻게 변하는지 살펴봅니다. 변동이 클수록 CV_edge가 커지며, 베팅 금액을 줄여야 합니다.
이전 예시를 계속해서 보겠습니다. 만약 CV_edge = 0.3이라면 (즉, 귀하의 추정이 30%의 불확실성이 있다는 것을 의미), 그러면 경험 켈리는 귀하에게 베팅할 것을 권장합니다:
f_empirical = 33.3% x (1 - 0.3) = 33.3% x 0.7 = 23.3%의 자금.
실제 운영에서 많은 기관은 심지어 "하프 켈리"(Half-Kelly)만 베팅합니다. 이는 2로 나누어 대략 12% 정도가 됩니다.장기적으로 보면, 조금 덜 벌어도 자금을 잃는 것보다 낫습니다.
5.4 완전한 Polymarket 거래 체계
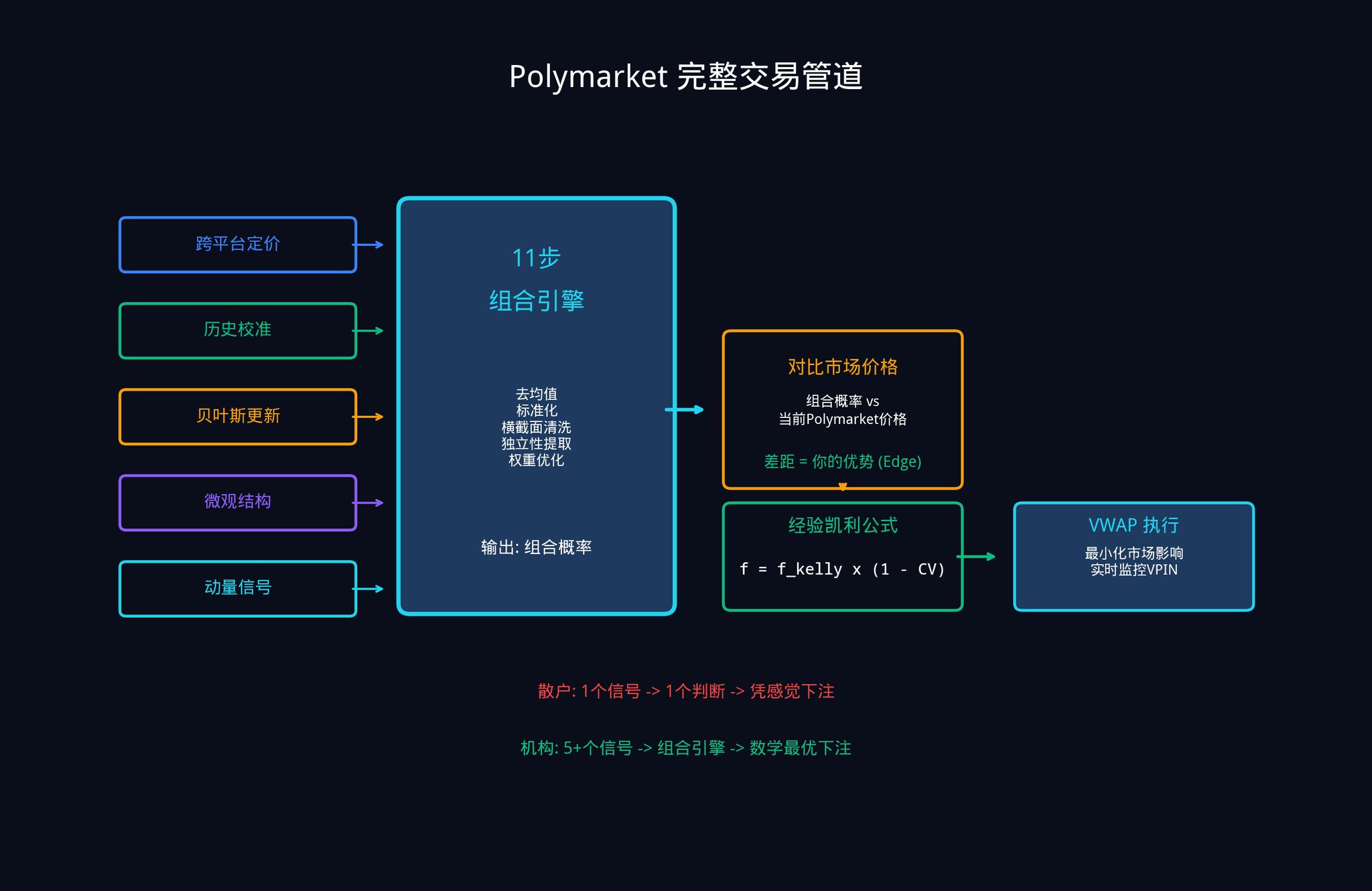
모든 것을 하나로 묶는 것은 다음과 같은 완전한 작업 흐름을 따릅니다:
1. 다섯 개 이상의 입력 신호, 각각이 내재 확률 추정을 생성
2. 11 단계의 조합 엔진을 통해 처리
3. 단일 가중 조합 확률을 출력
4. 현재 시장 가격과 비교하여 여러분의 엣지(Edge)를 계산
5. 경험적으로 켈리 공식을 사용하여 베팅 규모 결정
6. VWAP(거래량 가중 평균 가격)을 사용하여 실행을 최적화하고 대량 주문이 시장 가격에 미치는 영향을 줄입니다
7. 실시간으로 VPIN 변동을 모니터하여 내부자 거래자가 활발해질 때 전략을 즉시 조정
이 프레임워크는 예측 시장에 특히 가치가 있습니다. 그 이유는 매우 간단합니다: 대부분의 경쟁 상대가 단일 모델, 단일 데이터 소스, 단일 확률 추정을 사용하여 거래하기 때문입니다. 그러나 여러분은 이미 여러 약한 신호를 하나의 강력한 신호로 결합하는 방법을 알고 있습니다. 이것이 여러분의 구조적 이점입니다.
심화 연습 4:
관심 있는 Polymarket 계약을 선택하십시오. 적어도 세 가지 다른 관점(예: 크로스 플랫폼 가격 책정, 역사적 교정, 최근 뉴스 이벤트)에서 해당 계약의 확률을 각각 추정하십시오. 그런 다음 간단히 가중 평균값을 취하여 여러분의 조합 추정과 현재 시장 가격 간에 차이가 있는지 확인하십시오. 있으면, 축하합니다. 여러분은 방금 단순화된 알파 조합을 수동으로 완료했습니다.
Edward Thorp의 A Man for All Markets를 추천합니다. Thorp는 투자 분야에서 켈리 공식을 선두적으로 적용한 사람으로, 이 책에서 그는 어떻게 수학을 사용하여 카지노와 월스트리트에서 돈을 벌었는지를 매우 쉽게 설명합니다.
제6부: insiders.bot으로 이 시스템을 구현하십시오
여기까지 보았을 때, 여러분은 아마 생각할 것입니다: 이 시스템의 논리는 이해했지만, 혼자서는 어떻게하여 제로에서 구축할 수 있을까요?
좋은 소식은 여러분이 처음부터 시작할 필요가 없다는 것입니다.
insiders.bot (@insidersdotbot)을 하는 과정에서 이 기사에서 언급된 "액티브 매니지먼트 베이직 로" (즉, IR = IC x √N, 전체 시스템의 성능은 단일 신호의 정확도에 독립적인 신호 수의 제곱근을 곱한 것입니다)이 우리에게 매우 큰 영감을 주었습니다.
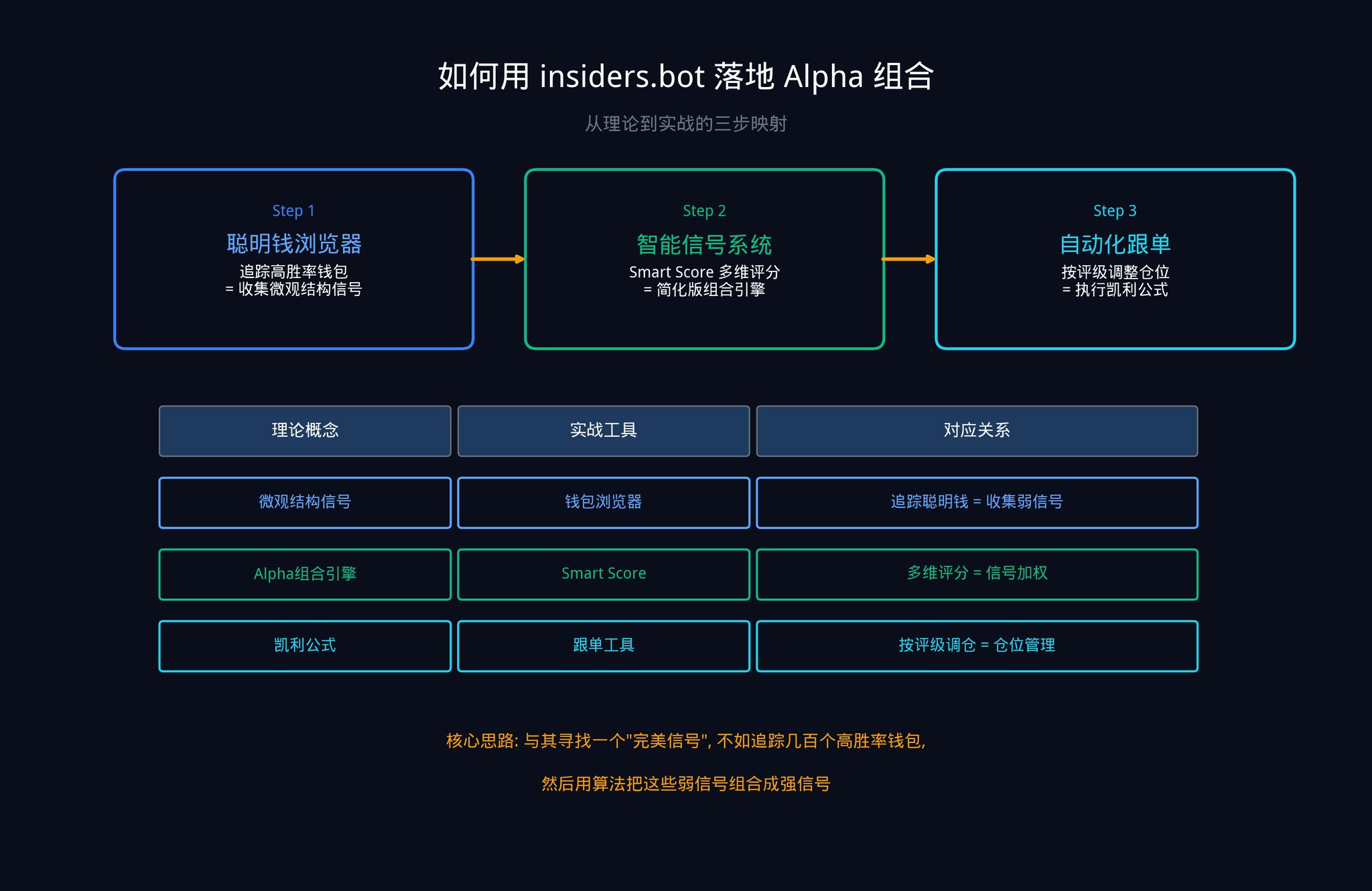
즉시 시작할 수 있는 세 가지 단계는 다음과 같습니다.
첫 번째 단계: 스마트 머니 브라우저를 사용하여 신호 원자재 수집
insiders.bot의 스마트 머니 브라우저를 열어보세요. 필터 패널을 통해 승률, 총 수익, 거래 빈도 등의 기준으로 Polymarket에서 가장 우수한 지갑을 찾을 수 있습니다.
이러한 지갑들의 각 이동은 여러분의 "미시 구조 신호"입니다 (다섯 가지 신호 유형 중 다섯 번째 유형을 기억하시나요?). 개별 지갑 신호는 약할 수 있습니다 (IC가 낮음), 그러나 수십 개의 지갑을 동시에 추적할 때 여러분은 이 글에 설명된 "신호 결합"을 실시하고 있습니다. 이것이 바로 액티브 매니지먼트 베이직 로의 핵심입니다: N이 클수록 IR이 높아집니다.
두 번째 단계: 스마트 신호 시스템을 활용하여 알파 조합 구현
우리의 스마트 신호 시스템 (SIGNALS 탭)은 본질적으로 간소화된 버전의 알파 조합 엔진입니다. 우수한 지갑이 대규모 거래를 할 때 시스템은 신호를 생성하고 Smart Score를 통해 과거 승률, 총 수익, 베팅 안정성, 분류 성과, 포지션 크기 등 여러 가지 기준을 종합하여 강도 평가를 제공합니다.
낮음: 기본 기준을 충족하지만 트레이더 이점이 일반적입니다. 낮은 IC 신호에 해당하며, 결합할 추가 신호가 필요합니다.
중간: 우수한 기록을 자랑하며 단호한 신념을 보여줍니다. 중간 IC 신호에 해당하며, 적당한 구성이 가능합니다.
높음: 최고 성과 지갑에서의 대규모 거래입니다. 높은 IC 신호에 해당하며, 조합 엔진은 높은 가중치를 부여합니다.
이 평가 시스템은 11-단계 엔진의 10번째 단계와 같은 작업을 수행합니다 (즉, 최적 가중치 설정, 즉, 각 신호의 독립적 기여 및 안정성에 따라 자금 배분 비율을 설정): 다양한 기준을 종합 평가하여 각 신호에 대해 다른 가중치를 할당합니다.
스텝 세 번째: 켈리 공식 실행하기
고등급 신호를 받으면 자동 거래 복제 도구를 사용하여 비율 또는 고정 금액으로 거래를 복제할 수 있습니다.
경험적 켈리 공식(f_empirical = f_kelly x (1 - CV_edge))으로 다시 한 번 생각해 보세요. 이 공식은 불확실성에 따라 베팅 비율을 조정해야 함을 나타냅니다: 추정치가 더 불확실할수록 베팅할 금액을 줄이셔야 합니다.
로우 등급 신호에는 포지션을 축소하고,
하이 등급 신호에는 조금 더 큰 포지션을 취할 수 있습니다. 감정이 아닌 수학이 결정을 내리도록 하세요.
맺음말
우리가 처음 던졌던 질문으로 돌아가 봅시다.
단일 신호는 약합니다. 그 하나의 완벽한 신호를 찾는 것은 올바른 방향을 찾는 것이 완전히 잘못된 것입니다.
활성 관리의 기본 법칙(IR = IC x √N)은 수학적으로 입증했습니다: 많은 약한 독립적인 신호를 결합하는 것이 강력한 신호를 찾는 것보다 나은 결과를 가져옵니다. 당신의 정보 비율은 실제로 독립적인 신호의 제곱근 수에 따라 증가합니다.
11 스텝 알파 포트폴리오 엔진은 각 신호의 독립적인 기여를 반영하여 최적의 가중치를 계산합니다. 이러한 가중치는 각 신호의 공유 분산을 벌절하며 신호 간의 상관 관계를 제거합니다.
시장을 예측하는 데 이 프레임워크는 다섯 개 이상의 내재 확률 신호를 단일의 조합 추정치로 변환합니다. 이 추정치가 임의의 구성요소보다 더 정확하다는 것이 입증되었습니다.
경험적 켈리 공식을 포지션 관리에 결합하면, 이 포지션은 실제로 얼마나 자신감을 가져야 하는지를 정확하게 반영하며, 당신이 얼마나 자신감을 느끼는지가 아니라 실제로 얼마나 자신감을 가져야 하는지를 보여줍니다.
복리의 가장 강력한 이점은 당신이 실제로 무엇을 알고 있는지에 기반한 가장 정직한 모델 위에 구축됩니다.
마지막으로, 다음 질문에 대해 생각해 보시기 바랍니다:
수백 개의 신호가 포함된 기관 트레이딩 데스크가 여전히 0.05에서 0.15 사이의 정보 비율만 달성할 수 있다면, 단일 모델에서 계속해서 고 신뢰도로 승자를 선택할 수 있다고 주장하는 어떤 시스템이 의미하는 것인가요?
고급 리딩 및 참고 자료
더 심층적인 연구를 진행하려는 경우, 아래는 몇 가지 고급 자료입니다:
입문:
Harvard Stat 110: 확률론 입문(무료 온라인 자료). 기초 확률론, 처음 6장만으로 충분합니다.
Edward Thorp, A Man for All Markets. 켈리 공식의 선구자이자 저자의 자서전으로, 수학이 어떻게 카지노와 월가에서 돈을 벌어오는지에 대해 쉽게 설명합니다.
고급:
Grinold & Kahn, Active Portfolio Management. 양적 투자 분야의 "성경"으로, 능동적 관리의 기본 법칙을 상세하게 유도했습니다.
MIT 18.06 선형대수학. Gilbert Strang 교수의 고전 강의로, 직교화를 이해하는 데 최적의 자료입니다.
최상급:
Marcos Lopez de Prado, Advances in Financial Machine Learning. 현대 양적 방법론의 필독서로, 특히 교차 검증, 특성 중요성 및 직교화 부분에 관한 내용을 다룹니다.
Easley, Lopez de Prado & O'Hara (2012), Flow Toxicity and Liquidity in a High-frequency World, Review of Financial Studies. VPIN 지표의 원문입니다.
원문 링크
BlockBeats 공식 커뮤니티에 참여하세요:
Telegram 구독 그룹:https://t.me/theblockbeats
Telegram 토론 그룹:https://t.me/BlockBeats_App
Twitter 공식 계정:https://twitter.com/BlockBeatsAsia







